代码运行过程
源代码- >解析器(parser)->AST->解释器(interperter)->字节码->编译器(TurboFan)->汇编 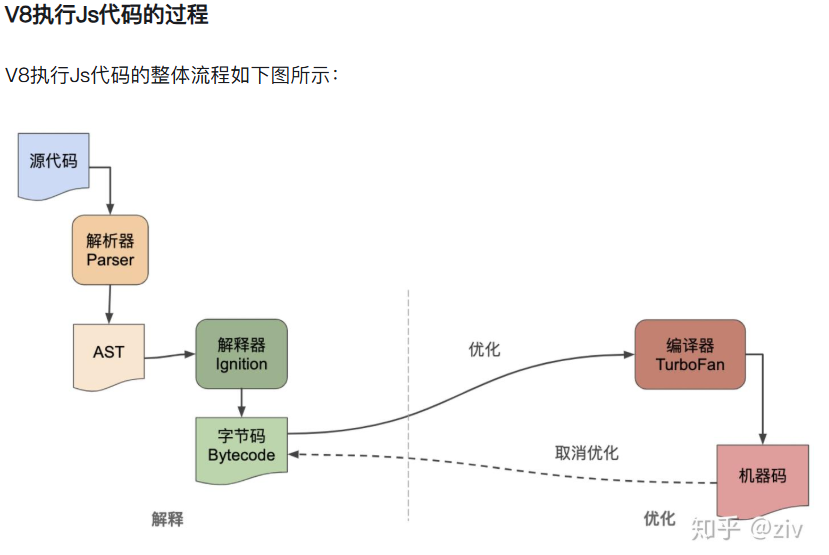
Parser生成抽象语法树
在Chrome中开始下载Javascript文件后,Parser就会开始并行在单独的线程上解析代码。这意味着解析可以在下载完成后仅几毫秒内完成,并生成AST。 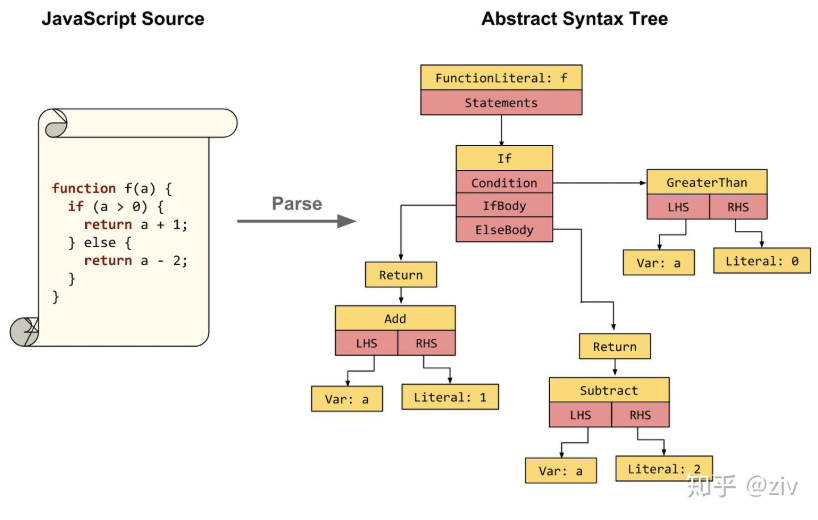
AST的生成过程是怎么样的呢?
1. 词法分析(lexical analysis):主要是将字符流(char stream) 转换成标记流(token stream),字符流就是我们一行一行的代码,token是指语法上不能再分的、最小的单个字符或者字符串。
2. 语法分析:将前面生成的token流根据语法规则,形成一个有元素层级嵌套的语法规则树,这个树就是AST。在此过程中,如果源代码不符合语法规则,则会终止,并抛出“语法错误”。
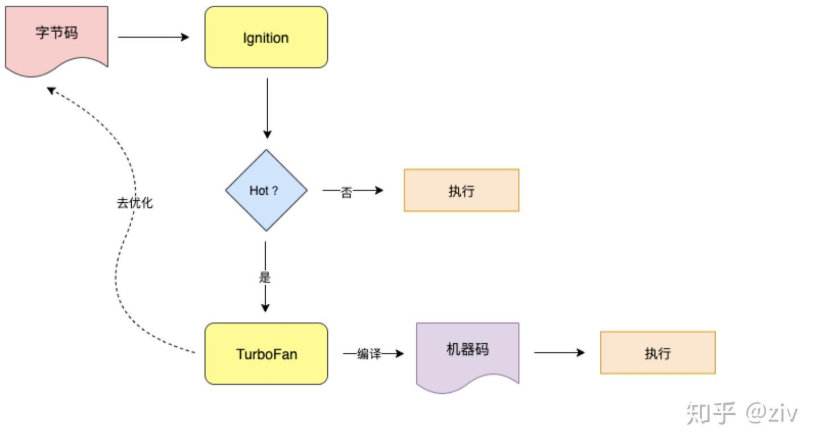 Ignition执行上一步生成的字节码,并记录代码运行的次数等信息,如果同一段代码执行了很多次,就会被标记为 “HotSpot”(热点代码),然后把这段代码发送给 编译器TurboFan,然后TurboFan把它编译为更高效的机器码储存起来,等到下次再执行到这段代码时,就会用现在的机器码替换原来的字节码进行执行,这样大大提升了代码的执行效率。
Ignition执行上一步生成的字节码,并记录代码运行的次数等信息,如果同一段代码执行了很多次,就会被标记为 “HotSpot”(热点代码),然后把这段代码发送给 编译器TurboFan,然后TurboFan把它编译为更高效的机器码储存起来,等到下次再执行到这段代码时,就会用现在的机器码替换原来的字节码进行执行,这样大大提升了代码的执行效率。
另外,当TurboFan判断一段代码不再为热点代码的时候,会执行去优化的过程,把优化的机器码丢掉,然后执行过程回到Ignition。
堆栈内存
栈内存ECS
计算机开辟的内存空间用于执行JS代码,也叫执行环境栈。代码在执行前会自身形成一个执行上下文,会进入栈中执行。执行完的代码可能会出栈
 上述过程(简单数据类型)在内存中会:
上述过程(简单数据类型)在内存中会:
- 创建一个值为
10 - 创建一个变量
x - 将变量和值关联在一起
变量对象(VO)
专门用来存储创建的值和变量。
- 如果内存中存在已经创建过的变量,便不会再创建,会直接进行关联。
- 一个变量同一时间只能关联一个值,但一个值可以关联多个变量。
ECS(执行环境栈)
用于管理执行上下文的栈结构,代码执行时会形成执行上下文并压入栈中,执行完毕后可能出栈。
简单数据类型在内存中的处理
以var x = 10为例:
- 首先进行声明动作(
var x,也叫declare)。 - 然后进行定义/赋值动作(
x = 10,也叫defined)。 在内存中会: - 创建一个值为
10。 - 创建一个变量
x。 - 将变量和值关联在一起。 还有类似
var y; console.log(y); // undefined的情况,变量y被声明但未赋值,所以打印undefined。
引用数据类型在内存中的处理
创建引用数据类型分三步:
- 开辟一个==堆内存==,并自动生成一个16进制的地址。
- 将创建的复杂值(对象等)本身的属性放到堆中。
- 把这个16进制的地址交给变量(存在==栈==中)。 比如:
var x = {n: 10};
var y = x;
y.n = 20;
console.log(x.n); // 20这里x和y指向同一块堆内存地址,所以修改y的属性,x的属性也会改变。
函数声明在内存中的声明
- 函数是==引用==类型。
- 在堆中开辟空间后,其中存储函数相关内容,并以字符串的形式保存。
- 函数在创建时的执行上下文就被保存,内存中以
[Scope](Scope.md)来存储其作用域等信息。 - 函数在执行时会形成全新的私有上下文并压入栈执行。
函数执行进栈后发生的事情
- 初始化自身的作用域链(包含上级上下文等,和全局执行上下文的查找机制类似)。
- 初始化
this指向:在全局函数调用中,this指向window(浏览器环境下)。 - 初始化形参集合:
arguments(类数组,存储函数调用时的实参等)。 - 形参赋值:将实参的值赋给对应的形参。
- 变量提升:只有通过
var声明的变量或者函数声明才会提升。变量提升是指变量的声明会被提升到当前作用域的顶部,但赋值不会提升;函数声明整体会被提升。 - 代码执行:按顺序执行函数内的代码。
- 执行完之后出栈:函数执行完毕,其执行上下文从执行环境栈中弹出,释放相关资源(当然,若有引用指向堆中的内容,堆内容不会立即释放)。
执行上下文Execution Context
- 全局执行上下文(GEC):window
- 函数执行上下文:每个函数有特有的环境,函数可以访问外面的变量(闭包)
- 块级执行上下文:在
{}中的let与const无法在外面访问到,ES6提出