基于标签的推荐系统(MovieLens)— 张量分解与LDA对比实验
基于 MovieLens 数据集,实现并对比了两类标签推荐算法:
- 张量分解(CP、Tucker)用于建模用户-电影-标签三元交互
- LDA 主题模型用于建模标签的潜在语义主题
一、项目目标与思路概览
- 目标:学习并比较“结构化交互建模(张量分解)”与“语义主题建模(LDA)”两类方法的标签推荐效果与代价。
- 场景:给定用户 u 和电影 i,预测其可能关联的标签 t(如“剧情紧凑”“科幻”“经典”等)。
- 思路:
- 三元交互张量建模:将用户-电影-标签构成三维张量X,通过分解得到低秩因子,完成潜在语义表示与打分预测。
- 主题语义建模:将标签视作词,用户与电影分别构成“文档”,用 LDA 学习主题分布,从主题-词分布中生成标签推荐。
二、数据预处理(data_preprocessing.py)
【处理目标与痛点】
- 标签现实中噪声多、同义多、长尾重:直接建模会显著拉低召回与泛化。
- 预处理追求三件事:清洗(去噪)、筛选(留强信号)、映射(可建模)。
【流水线与实现要点】
- 输入与最小依赖
- 必需 tags.csv(userId, movieId, tag[, timestamp]),代码按需依赖 ratings/movies 进行检查与展示。
- 清洗策略(TagCleaner.clean_tag_text)
- 统一小写、去除特殊字符与多余空格、长度过滤(<2 或 >50 直接丢弃)。
- 例:'Sci-Fi!!! ' → 'sci-fi';' epic classic ' → 'epic classic'。
- 有效标签筛选(TagCleaner.analyze_tags)
- 频次阈值 min_frequency:剔除极少出现的标签(弱信号/拼写异常)。
- 最小用户数 min_users:避免“单人自造词”导致过拟合。
- 可选 max_tags:仅保留最高频 Top-N,控制词表上限,利于大规模训练。
- 建议阈值(经验):ml-small 可取 min_frequency∈[3,5]、min_users∈[2,5];大数据适当上调频次、保留 max_tags=1k~5k。
- ID 映射与稳定性
- user_mapping, movie_mapping, tag_mapping 采用排序后的唯一值生成,确保训练/评估一致可复现。
- 注意:任何采样或过滤后需重新生成映射,避免索引错位。
- 张量构建与内存自适应(MovieLensLoader.create_tensor_data)
- 密集张量适用于小规模:X ∈ R^{U×I×T},dtype=float32。
- 内存估算:Mem_MB ≈ U×I×T×4 / 1024^2;若 >500MB 自动切换为稀疏。
- 稀疏表示(create_sparse_tensor_data):dict[(u,i,t)] → count,非零仅与观测条目线性相关,极大节省内存。
- 智能采样(MovieLensLoader.sample_data)
- 按比例 sample_ratio 抽样后,再选 Top 活跃用户与热门电影,最后可限制标签词表规模。
- 推荐顺序:ratio → users → movies → max_tags;能最大限度保留强交互信号。
- 复杂度与性能
- 清洗/统计:O(N) ~ O(N log N)(groupby/count)。
- 密集张量构建:O(N) 时间,O(U·I·T) 空间(受限于内存)。
- 稀疏张量构建:O(N) 时间与空间,适合长尾稀疏场景。
- 边界与鲁棒性
- 缺失/空标签直接过滤;重复三元组进行计数累加(更贴近多次标注强度)。
- 跨集映射:评估阶段仅对同时出现在 user/movie/tag 映射中的样本打分,避免冷启动噪音影响指标。
三、算法设计与实现
(1)张量分解(tensor_factorization.py)
【问题形式化】
- 三元交互张量 X(u,i,t) 表示“用户 u 给电影 i 赋予标签 t”的强度(计数)。
- 我们学习到低维因子后,对任一 (u,i) 对的每个标签 t 计算预测分数 s(u,i,t),供排序推荐。
【CP 分解(Parafac)】
- 模型:X ≈ Σ_{r=1..R} a_r ⊗ b_r ⊗ c_r,对应因子矩阵 U∈R^{U×R}、V∈R^{I×R}、T∈R^{T×R}。
- 预测:s(u,i,t) = <U[u], V[i], T[t]> ≈ dot(T, U[u]⊙V[i]) 后接 softmax 归一化用于排序。
- 实现要点
- 调用 tensorly.parafac(rank=R, n_iter_max=200, tol=1e-7, random_state=42)。
- 训练后保存 U,V,T;预测阶段采用逐点乘与投影,时间复杂度 O(R·T)。
- 优势与适用性
- 参数少、速度快、解释性好(每个维度可理解为“潜语义”)。
- 对复杂高阶交互的拟合能力有限,过小 R 可能欠拟合。
【Tucker 分解】
- 模型:X ≈ G ×1 U ×2 V ×3 T,其中 G∈R^{R×R×R} 为核心张量。
- 预测:先通过 einsum 将 U[u]、V[i] 与 G 融合,再与 T 投影到标签维度,表达力强。
- 实现要点
- tensorly.tucker(rank=[R,R,R], n_iter_max=150, tol=1e-7)。
- 预测复杂度略高于 CP,但能建模维度间耦合(核心张量提供“交互的交互”)。
- 优势与适用性
- 表达能力强、对噪声更鲁棒;但参数与训练时间更大,易过拟合,需更强正则与早停。
【稀疏-CP(ALS 自实现)】
- 背景:U·I·T 极大时,密集分解不可行,需仅在观测三元组上优化。
- 目标:最小化 Σ_{(u,i,t)∈Ω} (X[u,i,t] − <U[u]⊙V[i], T[t]>)^2 + λ(||U||^2+||V||^2+||T||^2)。
- 实现细节
- 初始化:Xavier;数据结构:为每个 u/i/t 预聚合相邻索引,减少重复检索。
- ALS 更新:固定两组、更新一组,解正规方程 (A^T A + λI)x = A^T b;全程向量化。
- 收敛:每 10 次计算损失,改善 < 1e-5 早停;max_iter 可配置。
- 预测同 CP:scores = T dot (U[u]⊙V[i]),softmax 排序。
- 工程取舍
- 线性依赖于非零元素 nnz,适合 ml-25m。
- 可能略逊于密集最优,但在成本-精度间取得良好平衡。
(2)LDA 主题模型(lda_recommendation.py)
【思想与建模】
- 将“标签”视作词,将“用户”和“电影”分别视作文档,学习文档-主题分布 θ 与主题-词分布 φ。
- 推荐逻辑:对 (u,i) 融合其主题偏好,进而在 φ 上生成标签排序。
【实现流程】
- 文档构造:按 userId / movieId 聚合 cleaned_tag,拼接成“文本”。
- 向量化:CountVectorizer(min_df=2, max_features≤5000) 构建词频矩阵,过滤极稀词。
- 训练:sklearn LatentDirichletAllocation(n_components=K, doc_topic_prior=α, topic_word_prior=β, max_iter, batch)。
- 主题解释:打印每个主题 top-words,用于报告展示与错误分析。
- 推荐细节
- θ_u = user topic dist;θ_i = movie topic dist;合并 θ_ui = (θ_u + θ_i)/2。
- 标签打分:p(tag) ∝ θ_ui · φ(components_),按概率排序取 Top-K。
- 词表对齐:仅返回同时存在于词表与 tag_to_idx 的标签,确保一致性。
- 优势与适用性
- 语义可解释性强、对冷启动友好(若用户/电影缺历史则退化为均匀分布)。
- 对主题数敏感,短文本场景受限;依赖文本假设,可能与交互强度不完全一致。
【超参与调优建议】
- R(因子数):小数据 30~50;大数据/复杂关系 50~100。
- K(主题数):20~80,过小欠分辨、过大易稀疏;结合困惑度与可解释性取折中。
- λ(正则):0.001~0.05;数据越稀疏越需要正则。
- 迭代:CP/Tucker 150~300;ALS 50~150;LDA 50~150。
- 实践技巧:先用较小 R/K 快速对齐流程,再加大参数做最终跑表。
【何时选谁?】
- 更看重交互结构:优先 CP/Tucker;数据稀疏大规模:稀疏-CP。
- 更看重语义解释/冷启动:优先 LDA;也可将 LDA 主题作为张量侧特征融合。
四、评估指标与流程
【数据切分策略】
- 随机划分(main_comparison.py):train_test_split(test_size=0.2, seed=42),快速基线。
- 时间划分(TensorEvaluator.train_test_split_temporal):按时间先后切分,更贴近线上部署。
- 建议:报告对比两种切分的指标差异,突出时序泄露的影响与业务意义。
【指标定义与计算】
以用户-电影为单位进行集合命中评估,最终对全体样本做微平均(micro-averaging)。
对 LDA(多标签集合):
- Precision@K = 命中总数 / 预测总数
- Recall@K = 命中总数 / 测试真值标签总数
- F1@K = 2PR / (P+R)
- 实现:按 (userId, movieId) 分组,将 cleaned_tag 作为真集,对比 top-K 推荐集合。
对张量分解(简化近似)
- 当前实现将每条测试 (u,i,t) 视作单标签事件,计算 top-K 是否命中 true tag,precision≈recall≈hit-rate。
- 局限:未对“同一 (u,i) 的多真标签”做集合评估,偏向乐观。可在后续按 LDA 的评估方式做多标签聚合,得到更一致的比较。
K 的选择:常用 K∈{5,10,20};报告中建议展示指标-曲线(随 K 变化),体现排序稳健性。
【流程串联与产出物】
- 加载与清洗 → 采样(可选)→ 映射与张量/文档构建 → 模型训练(CP/Tucker/稀疏-CP/LDA)→ 评估与对比 → 可视化出图。
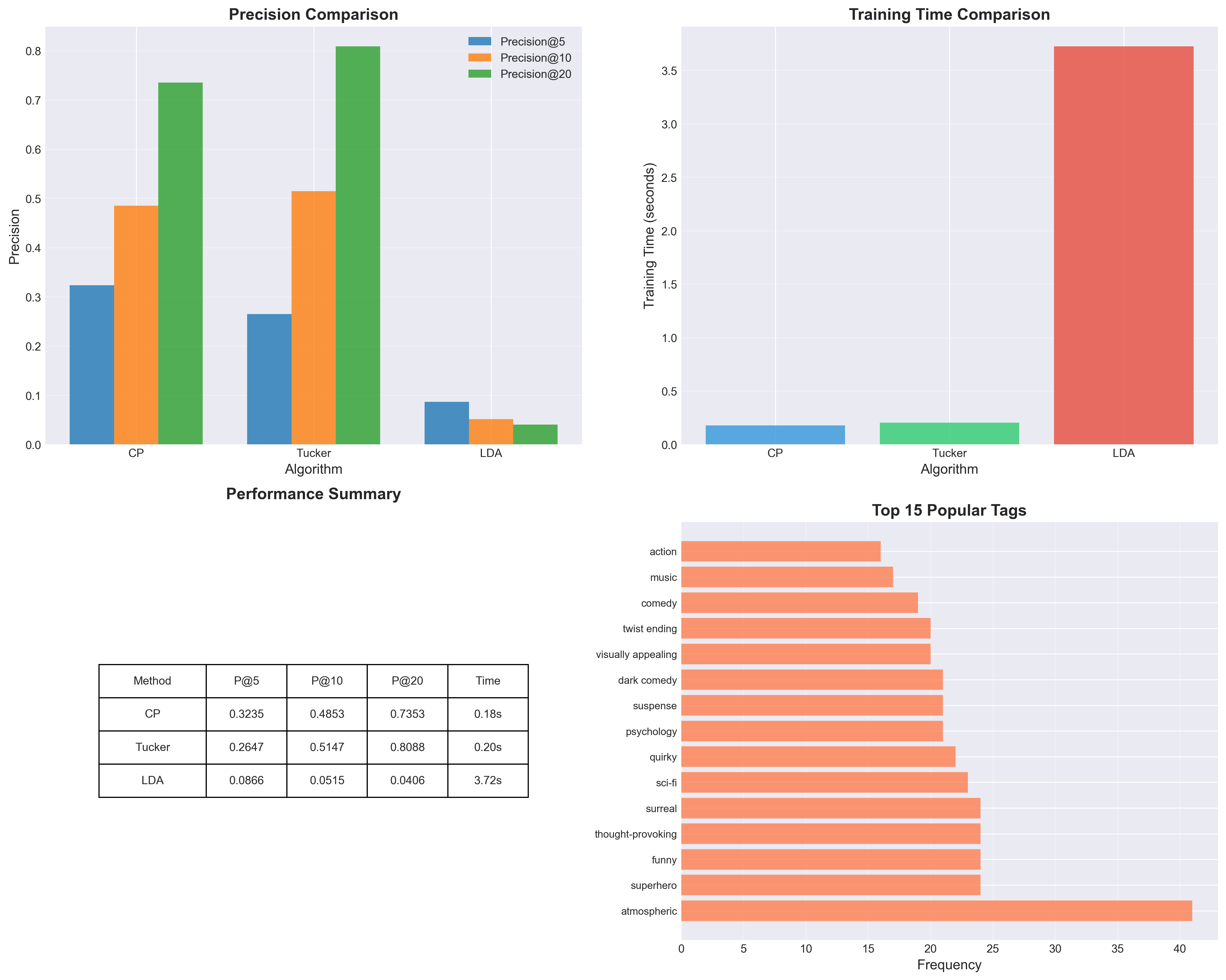
- recommendation_comparison_results.png 四宫格解读
- 左上(Precision@K):观察随 K 变化的相对优势;CP 更稳、Tucker 在高维时更强,LDA 受主题数影响。
- 右上(训练时间):体现“表达力 vs 代价”的权衡;为工程落地提供依据。
- 左下(摘要表):一图复盘关键指标,便于在答辩中快速引用数值。
- 右下(Top-15 标签分布):展示数据语义谱系,帮助解释模型行为与错误来源。
- 置信度与稳健性(可作为加分点在汇报中说明)
- 建议做 3~5 次不同随机种子的重复实验,报告均值±标准差。
- 可选:对用户-电影对做 bootstrap 采样,给出指标置信区间(未在代码中实现,报告可口头说明方法与价值)。
五、调参与性能建议
- 精度优先
- 增加 n_factors(如 30->40)
- 提高迭代次数(CP/Tucker:n_iter_max;稀疏ALS:max_iter)
- 适当降低 TagCleaner 阈值(min_frequency、min_users)
- 速度/内存优先
- 启用 use_sparse(大数据集自动)
- 使用 sample_config 采样活跃用户/热门电影
- 降低 LDA n_topics 与 max_iter
- 可解释性
- 使用 LDA 打印主题 top-words(print_top_topics)
- 张量分解因子可用于分析用户/电影/标签的潜在维度
六、结果解读与展示建议
- 图表 recommendation_comparison_results.png
- 左上:Precision@5/10/20 对比
- 右上:训练时间对比(秒)
- 左下:关键指标摘要表
- 右下:Top-15 标签分布
- 汇报要点
- 数据清理与采样策略如何影响有效信号与泛化
- CP 与 Tucker 的表达力-代价权衡
- LDA 在主题可解释性与冷启动上的优势
- 小数据集与大数据集下最佳实践的差异