5.1 树
5.1.1 树的定义
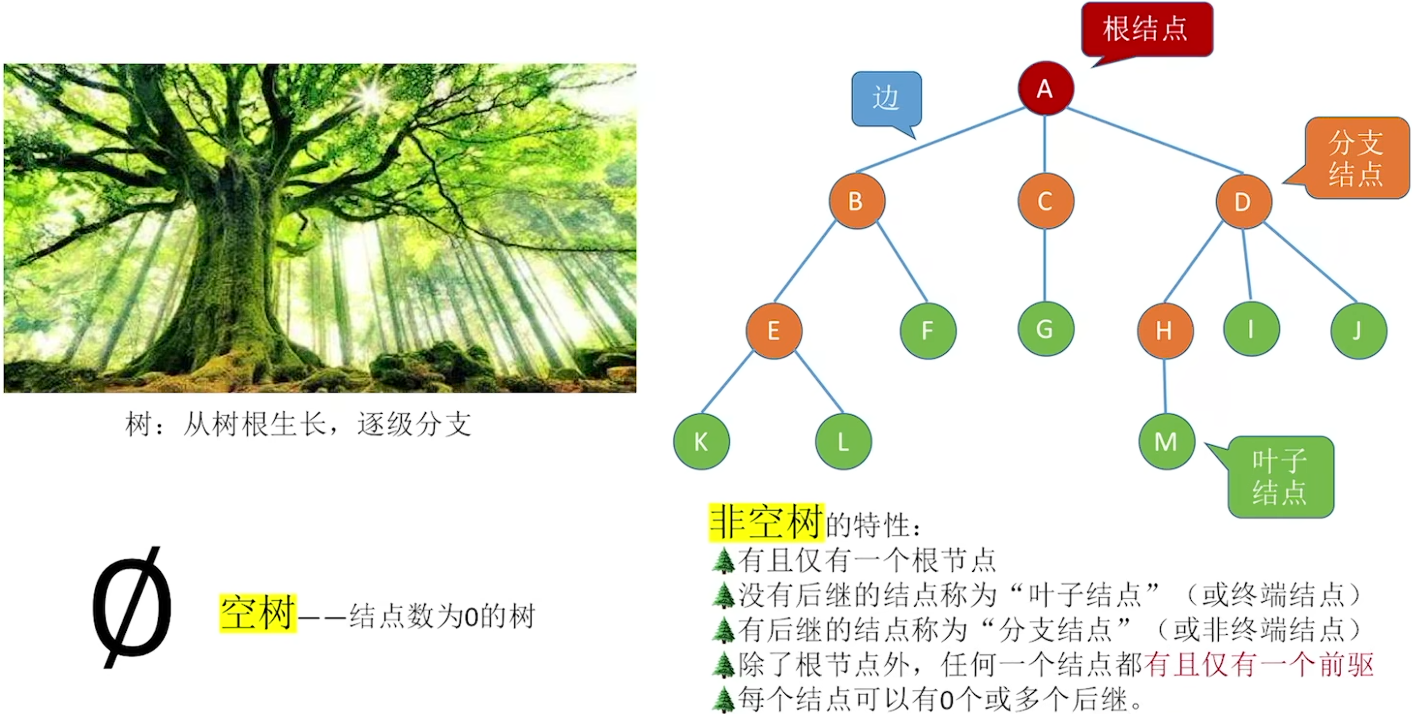
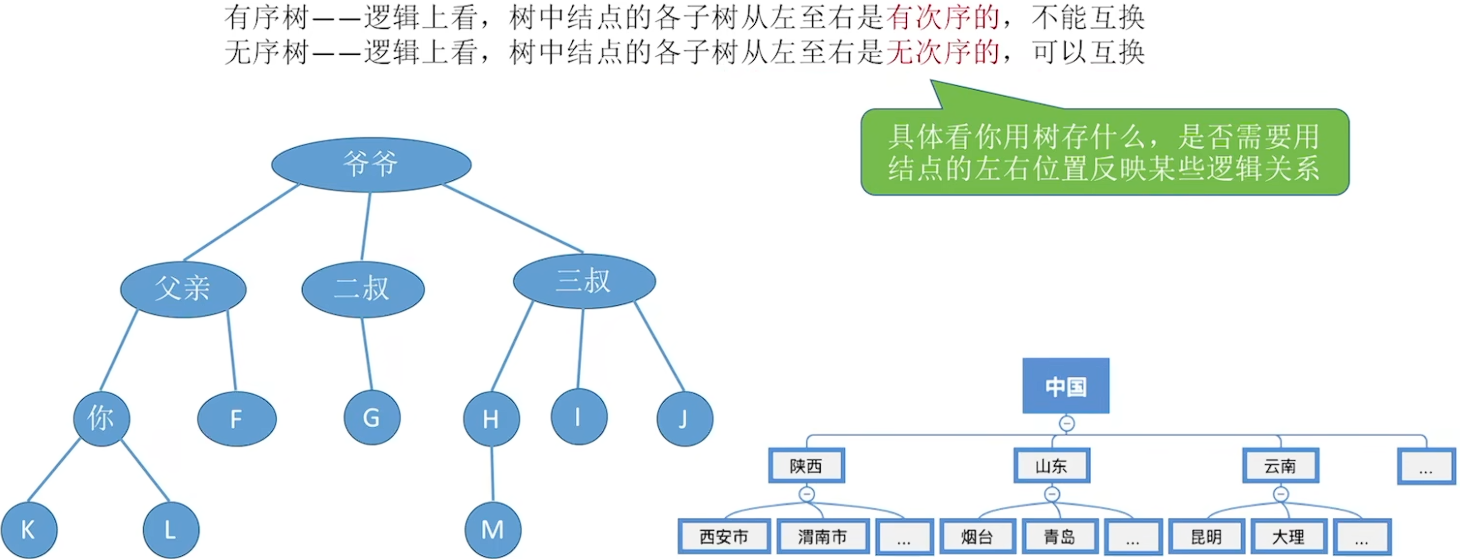
5.1.2 基本术语
路径是有向边 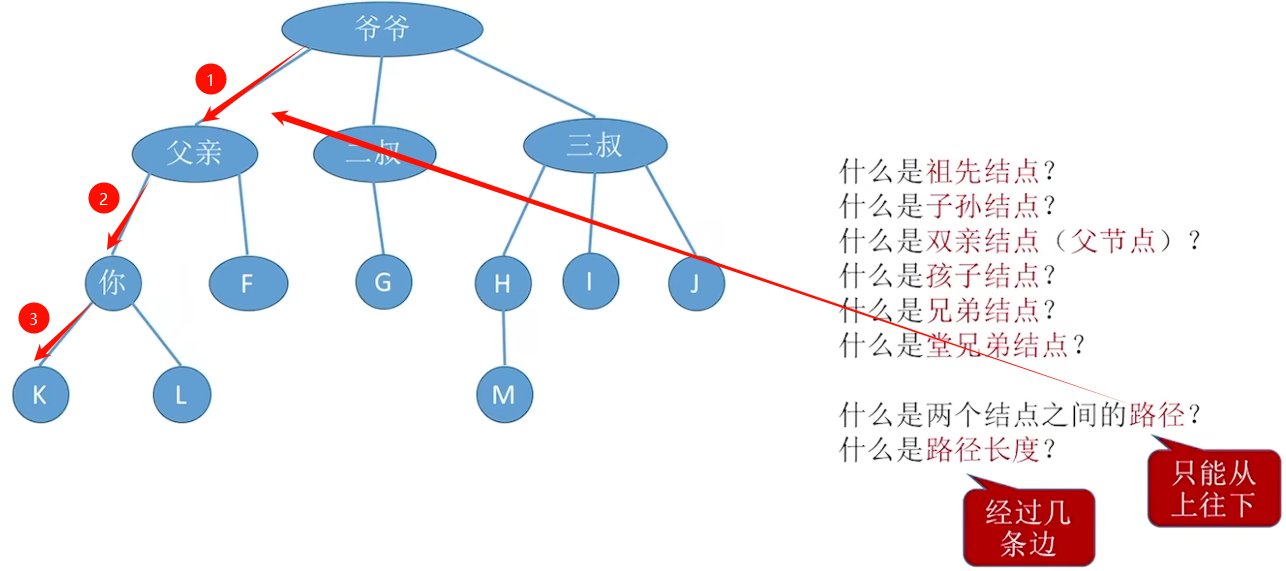
有序数与无序树
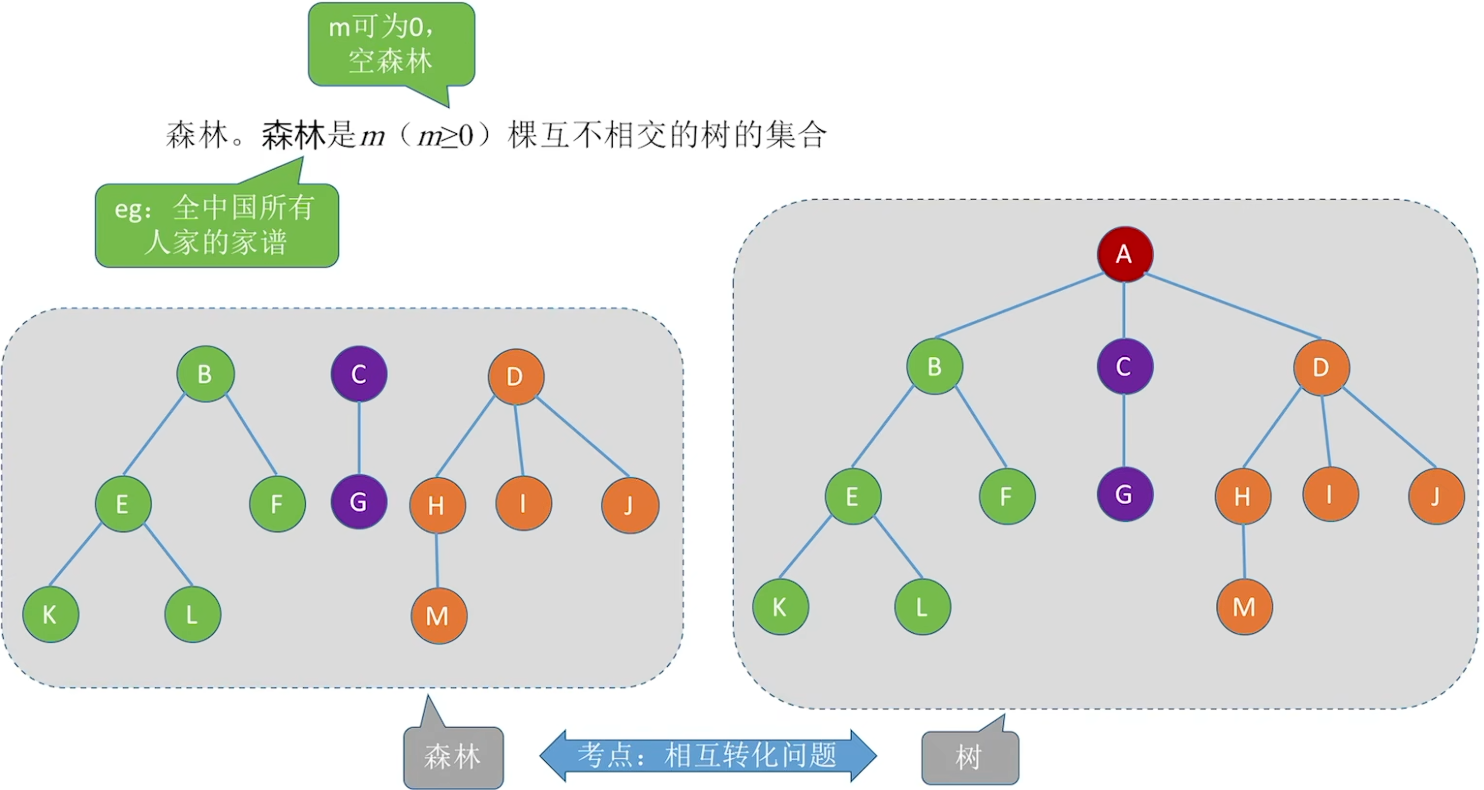
森林
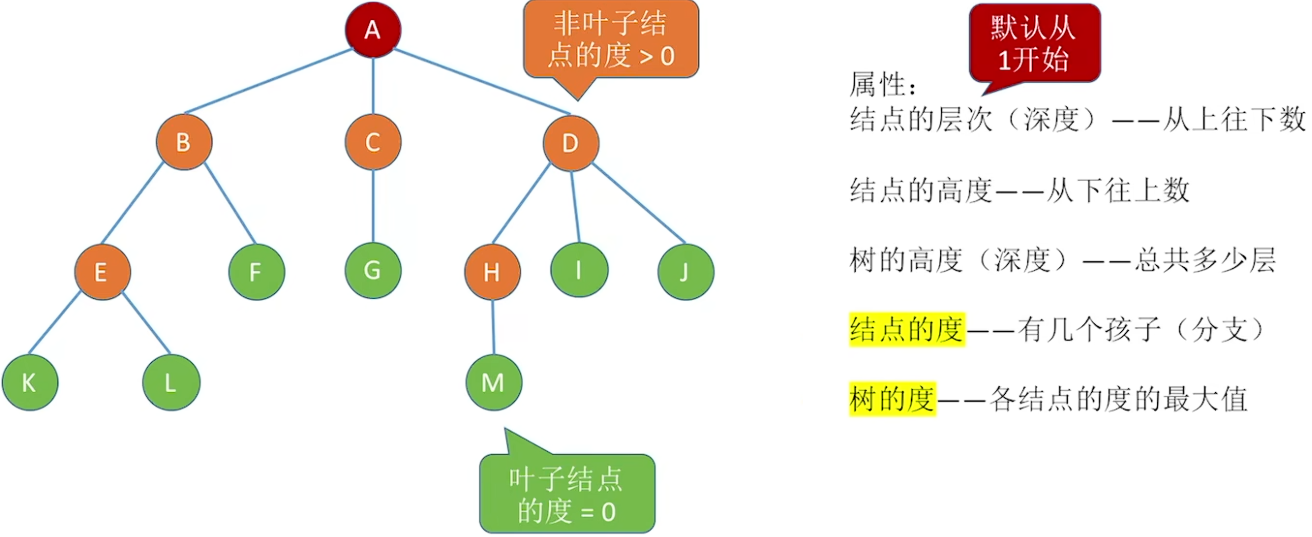
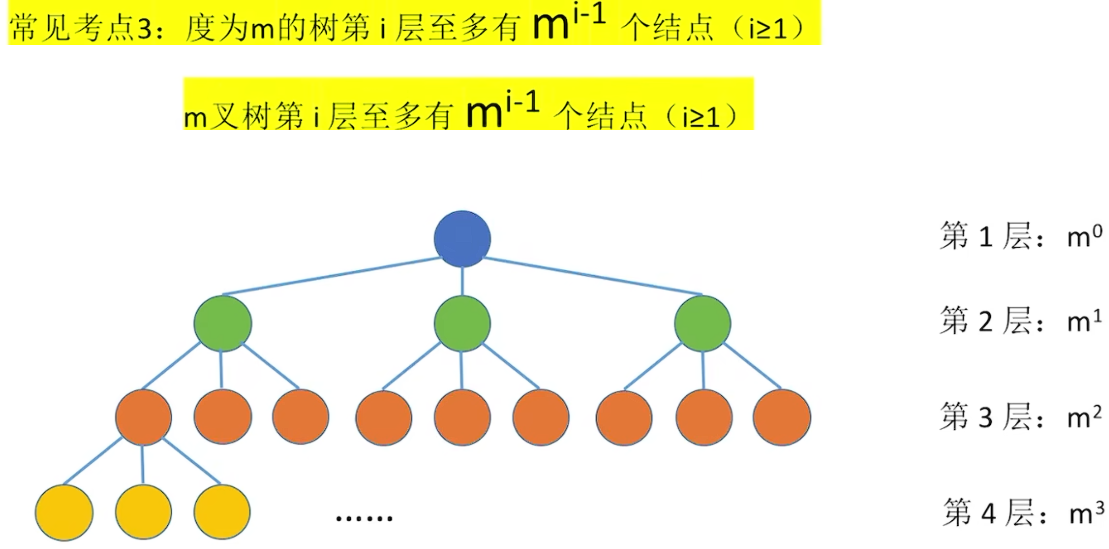
5.1.3 树的性质
除了根结点,每个结点都有一个入度 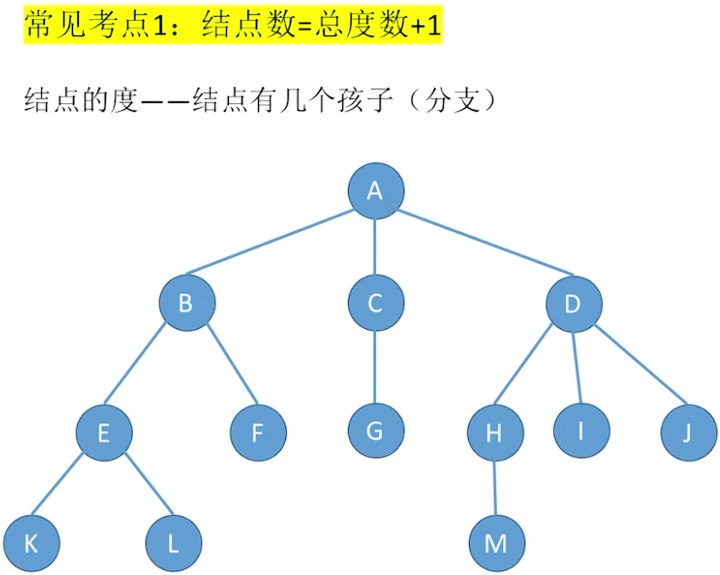
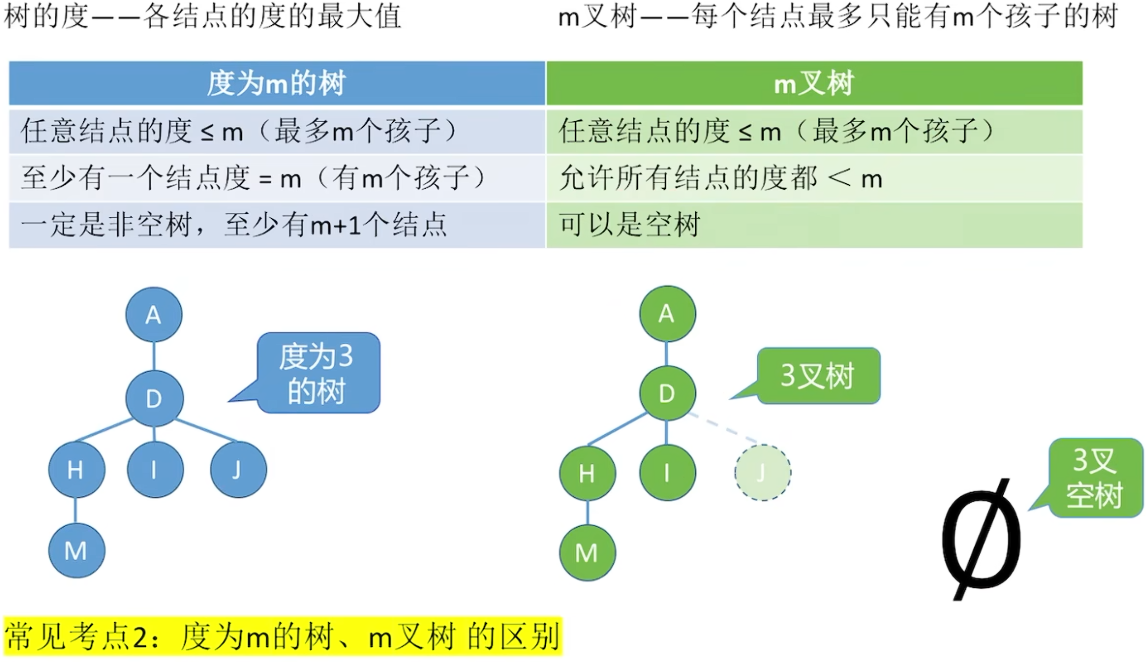



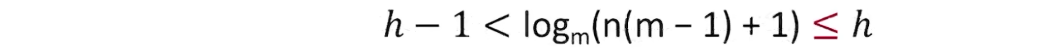
5.2 二叉树
5.2.1 基本概念
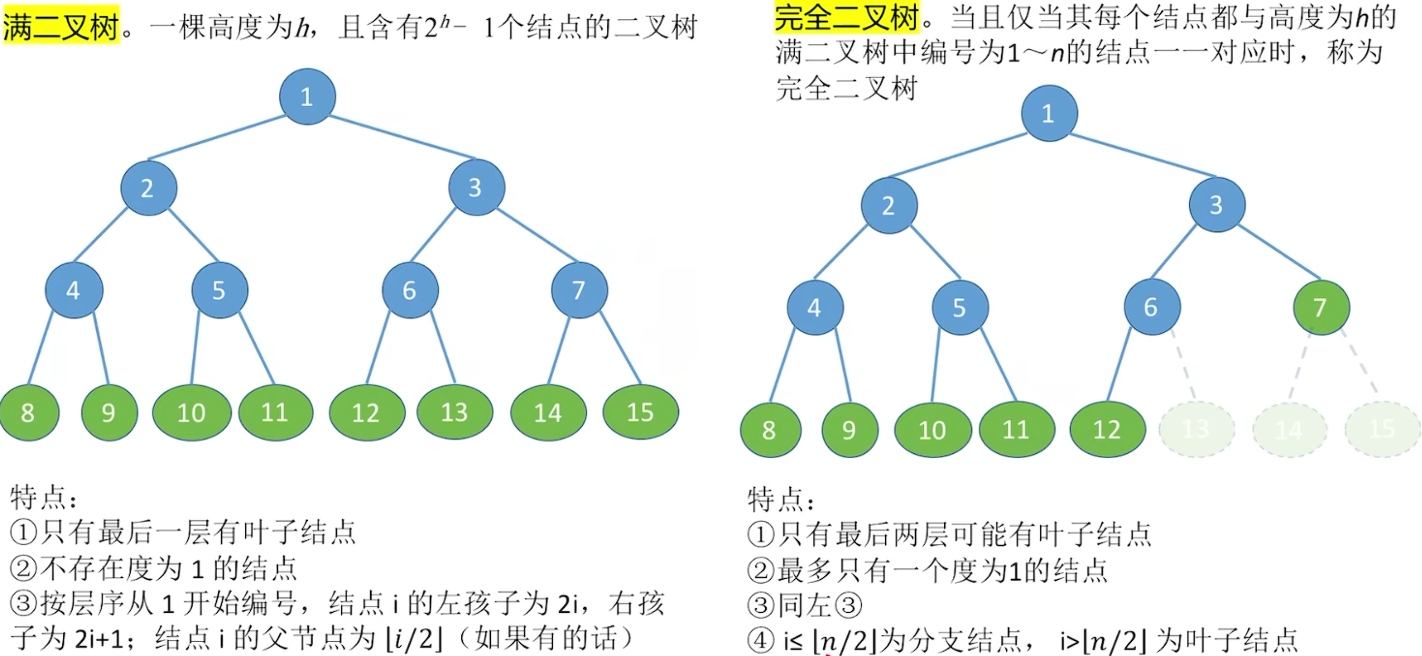
满二叉树与完全二叉树
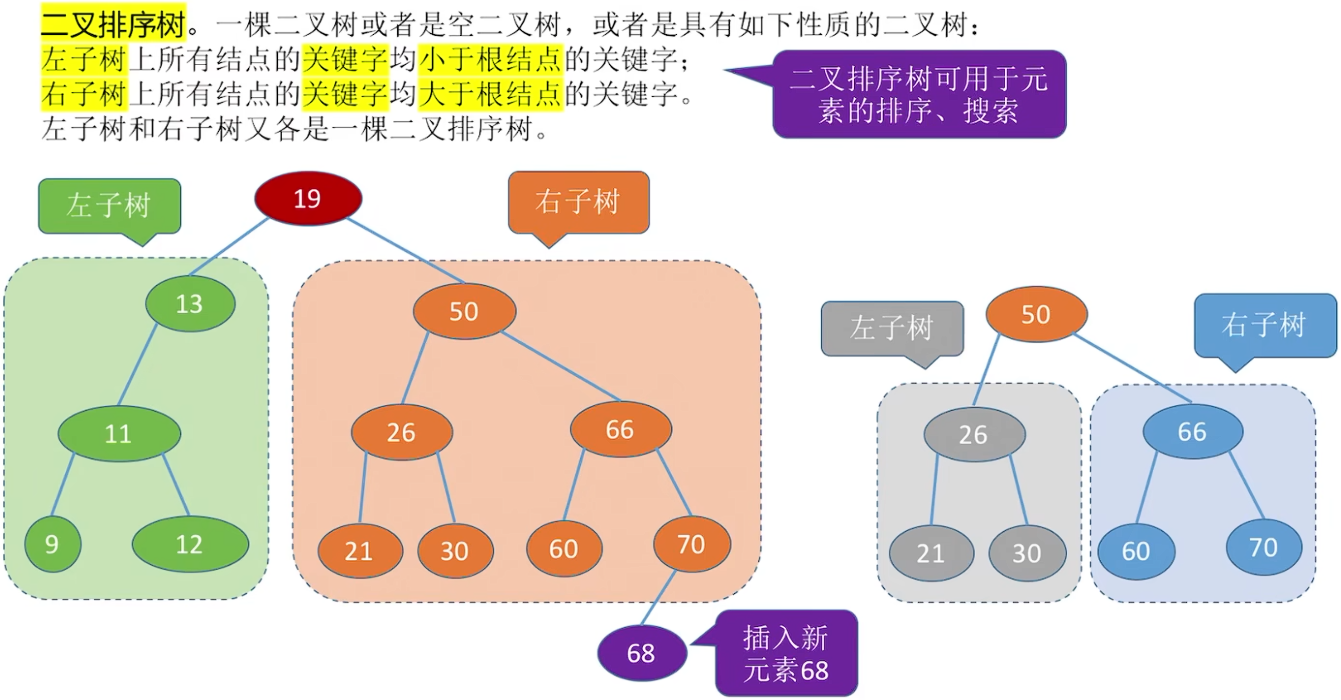
二叉排序树
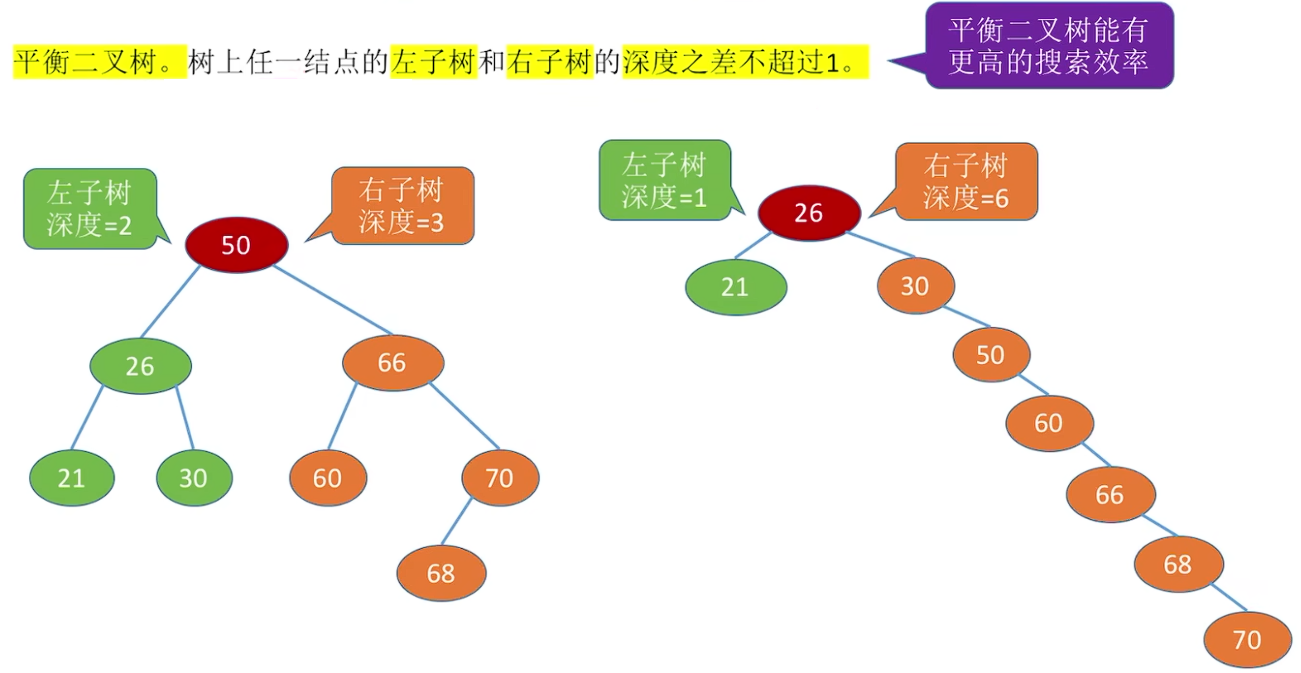
平衡二叉树
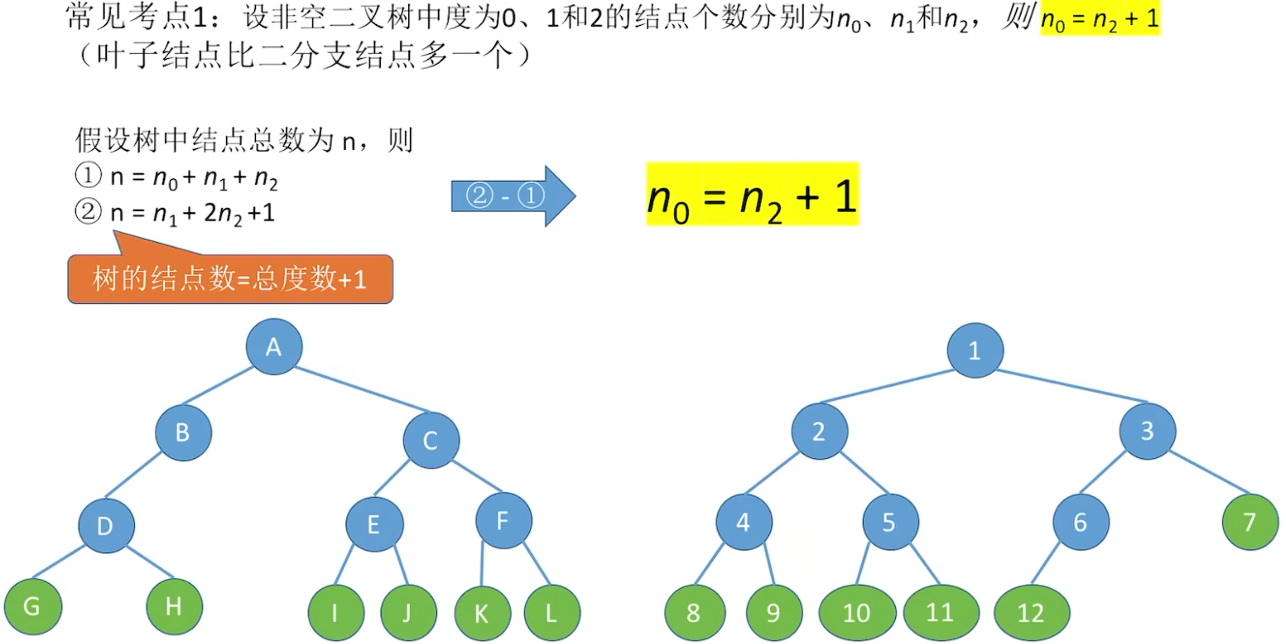
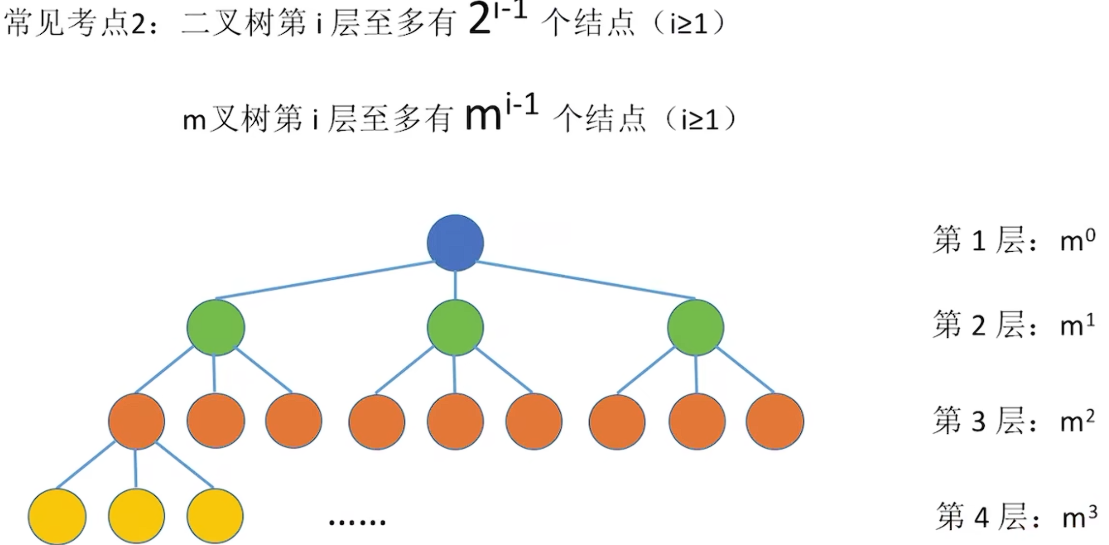
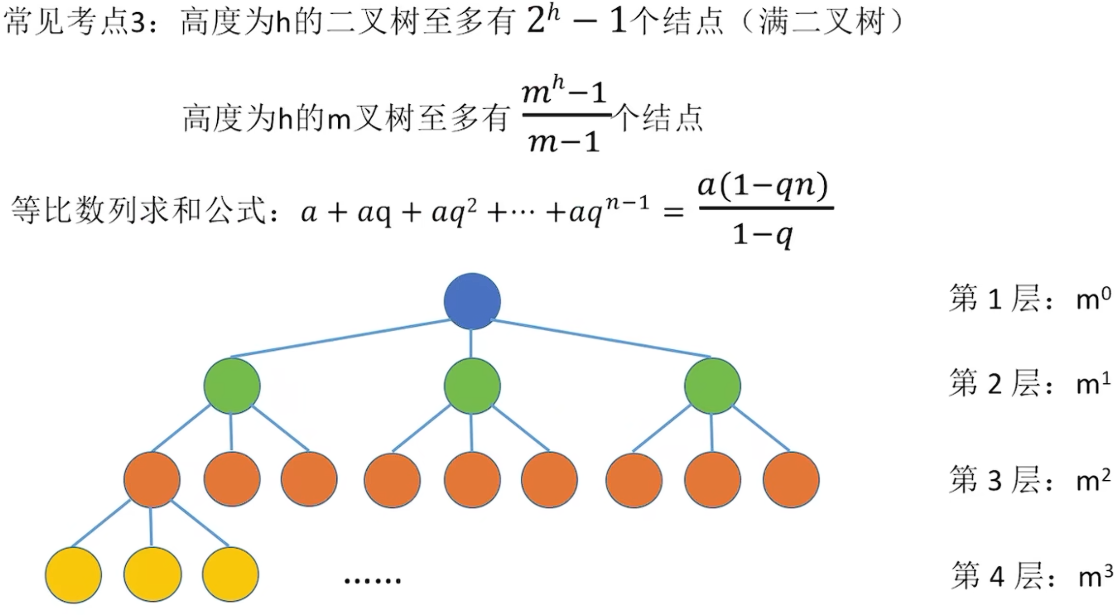
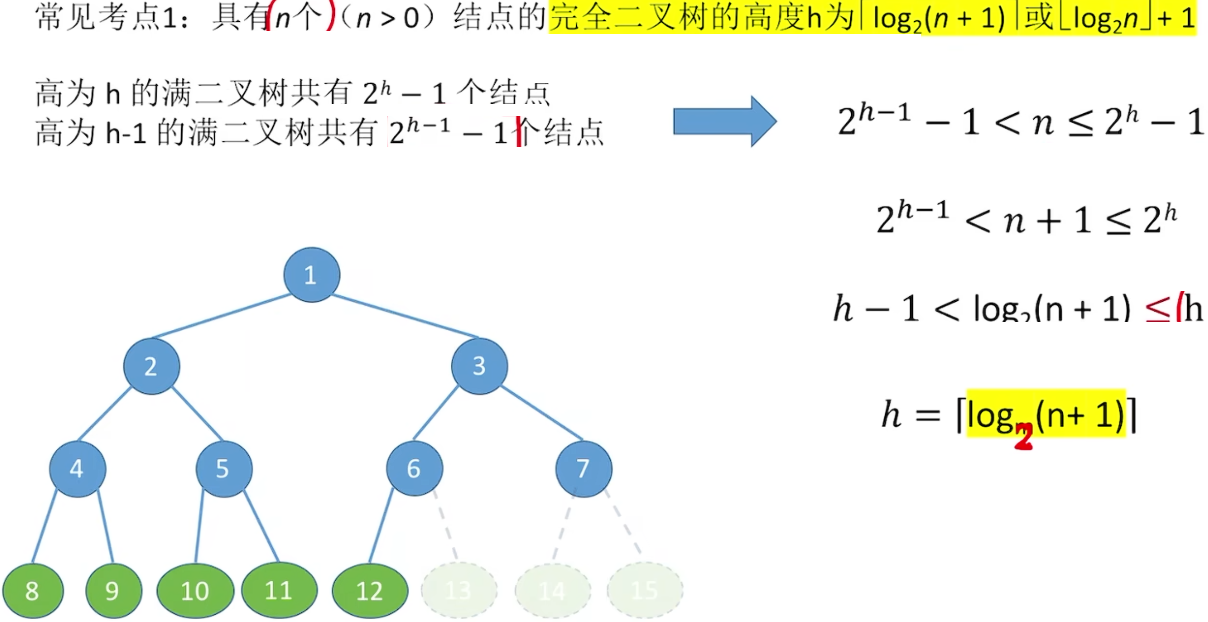
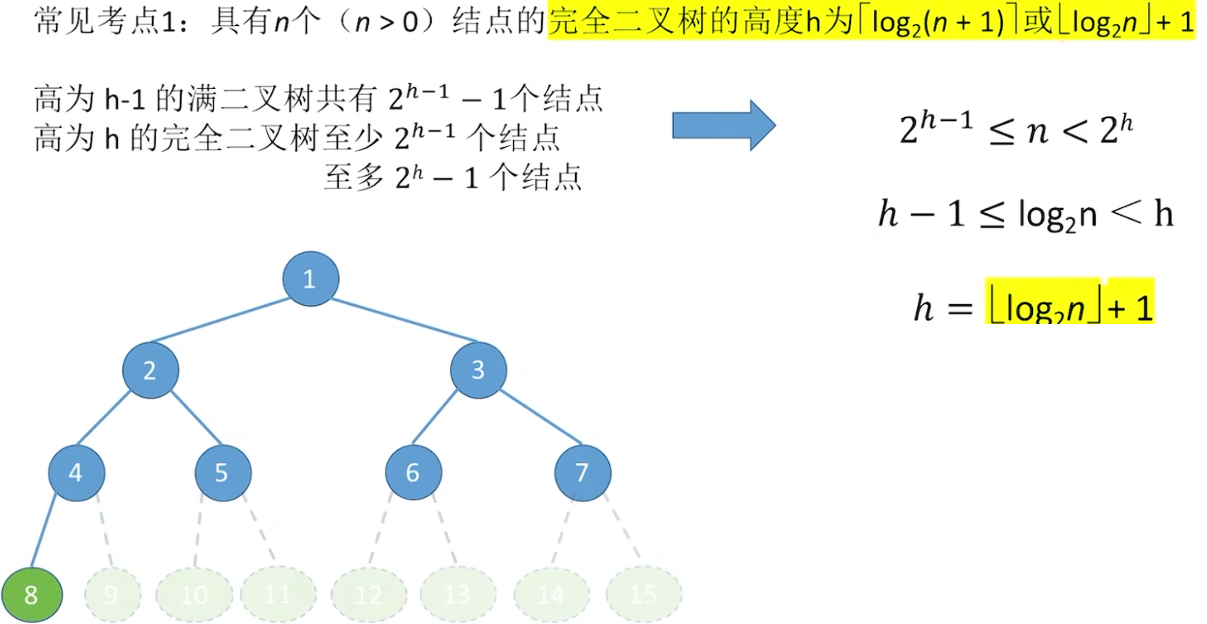
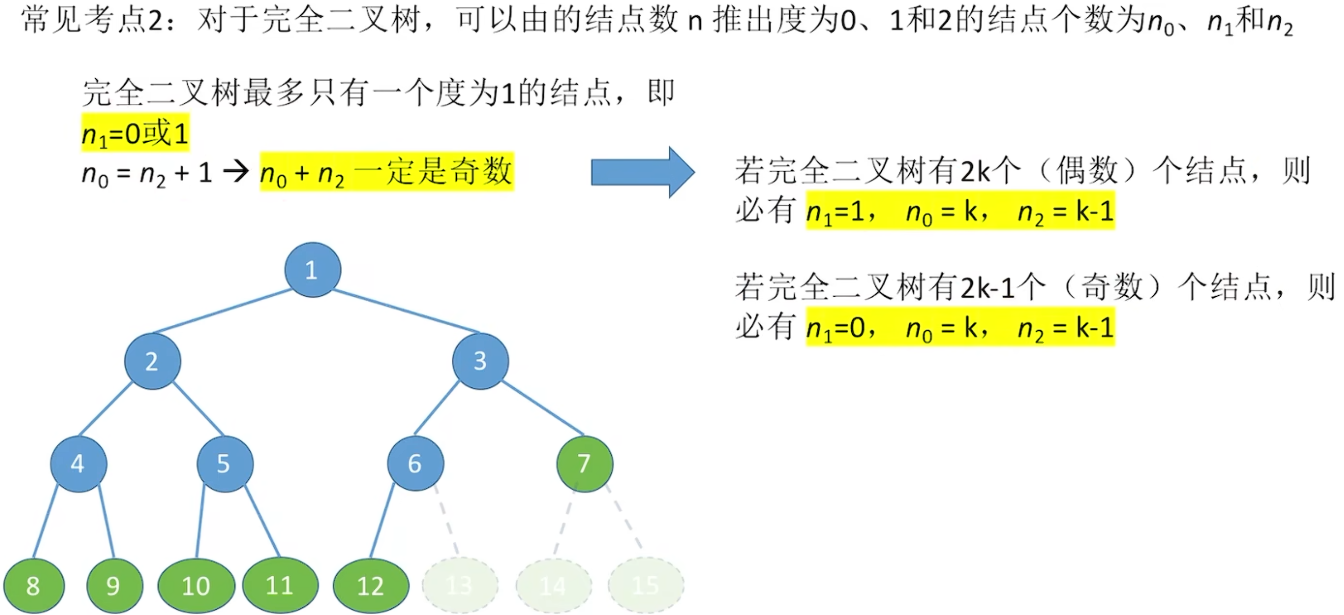
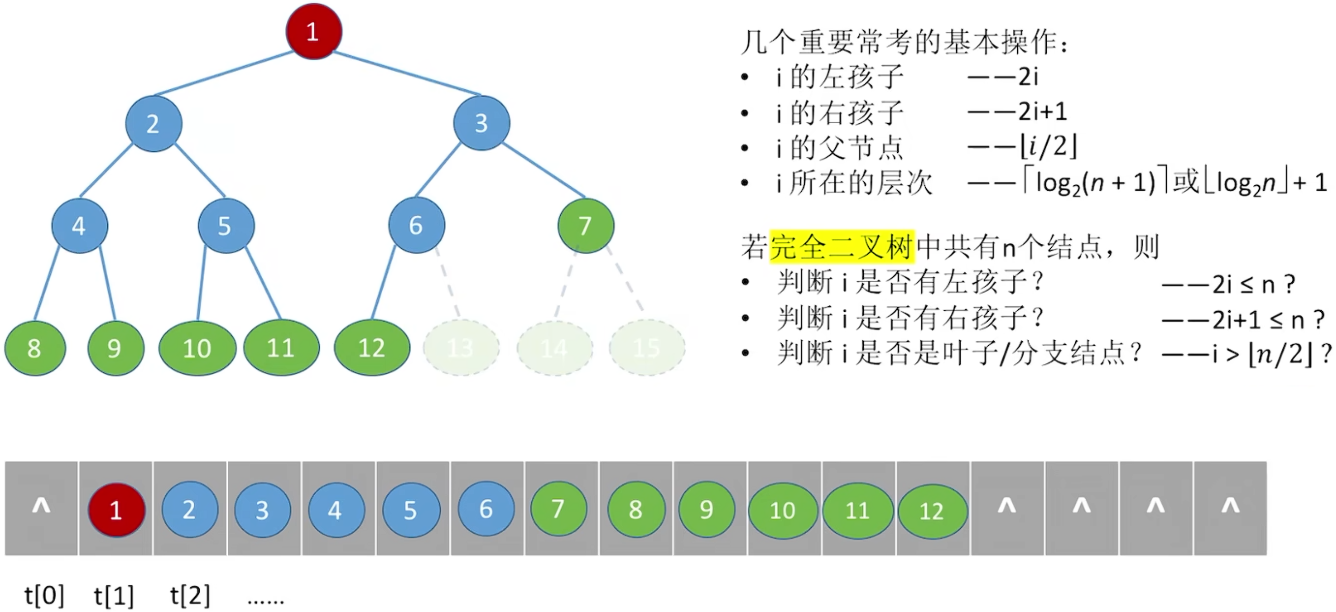
5.2.2 二叉树的性质
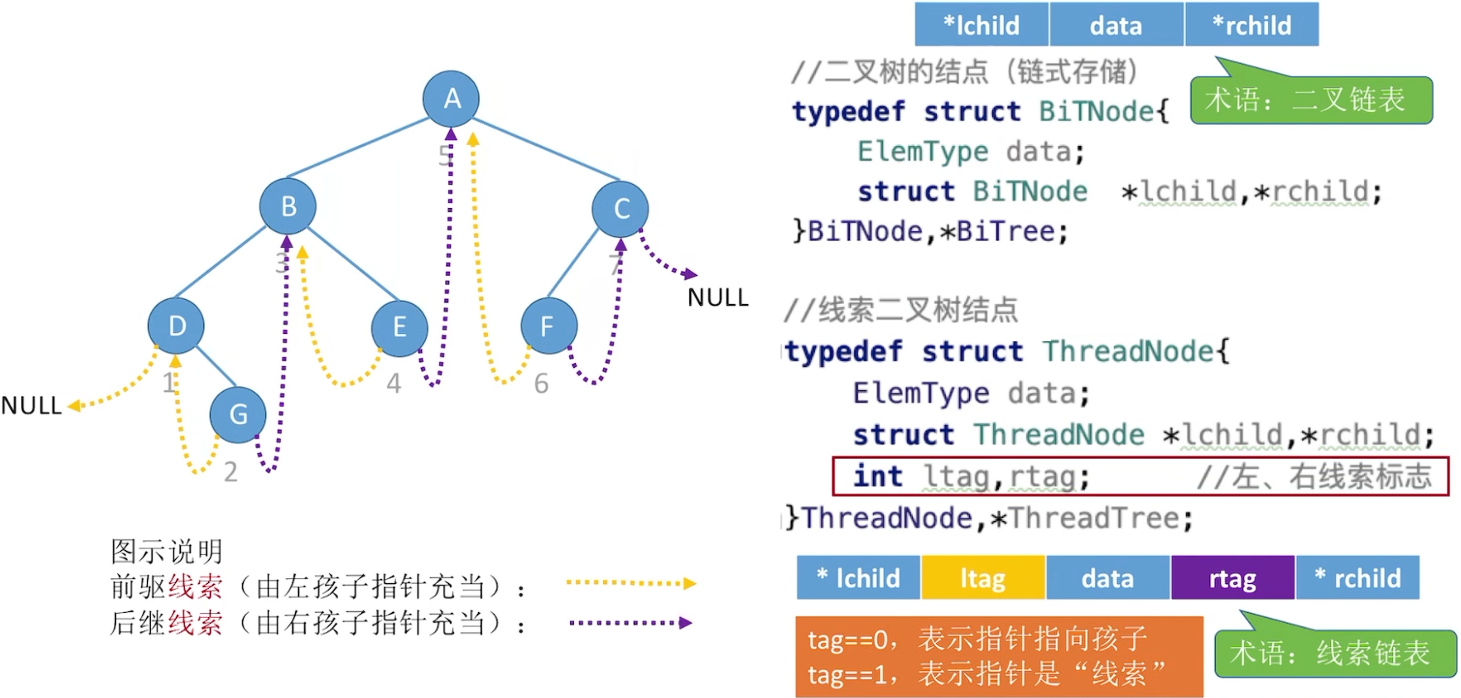
5.2.3 二叉树的存储结构
顺序存储
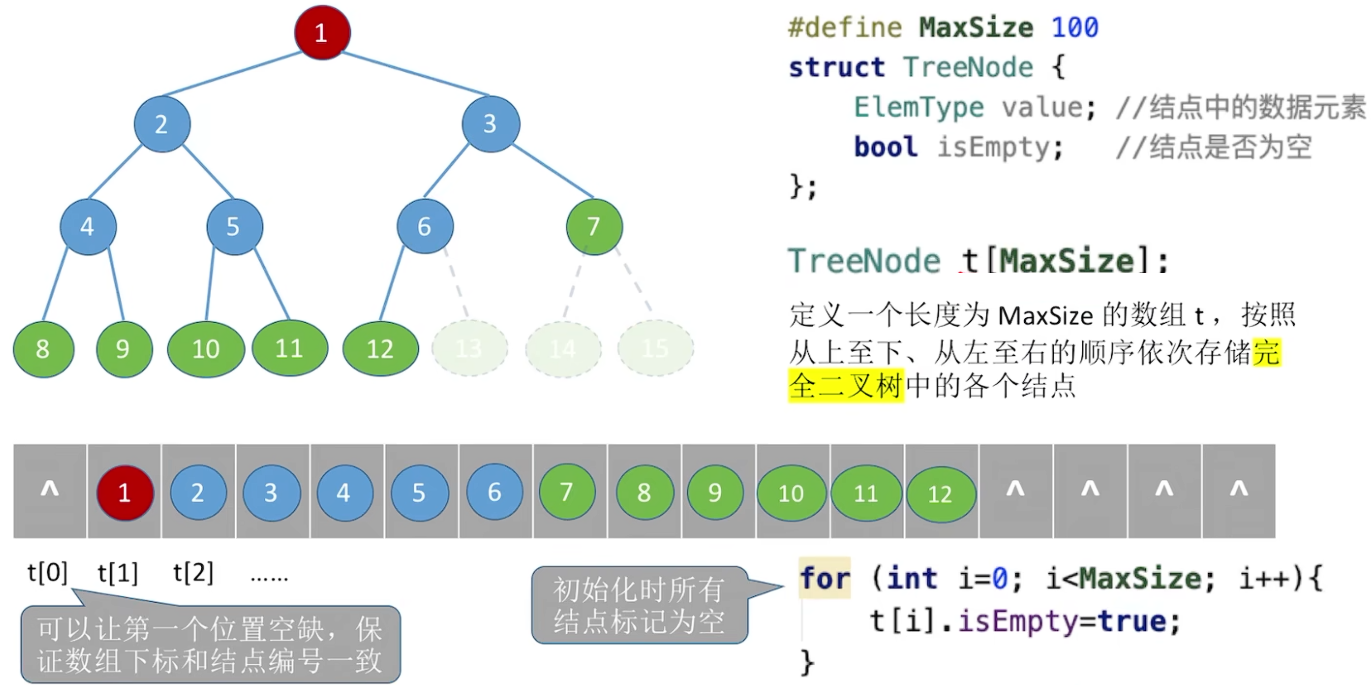
 使用顺序存储二叉树来存储,只适合完全二叉树,会有大量空位:
使用顺序存储二叉树来存储,只适合完全二叉树,会有大量空位: 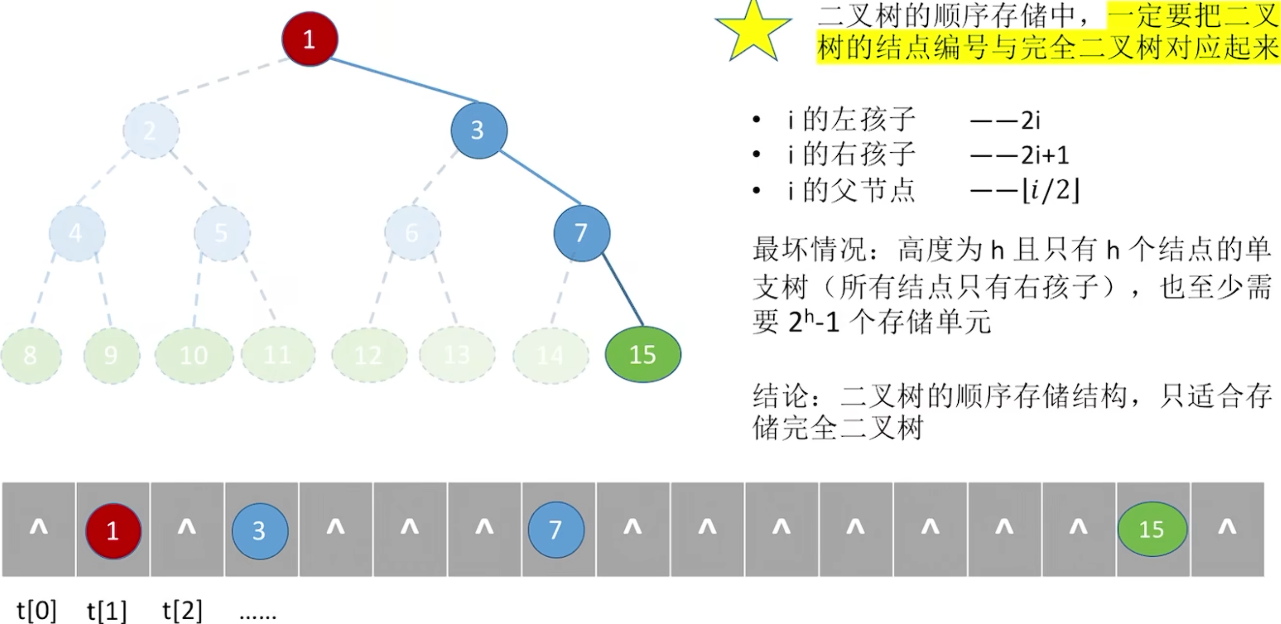
链式存储
n个结点,有n-1个指针指向结点(根结点没有),每个结点有两个指针域,共有2n个,剩余的n+1个指针域为null: 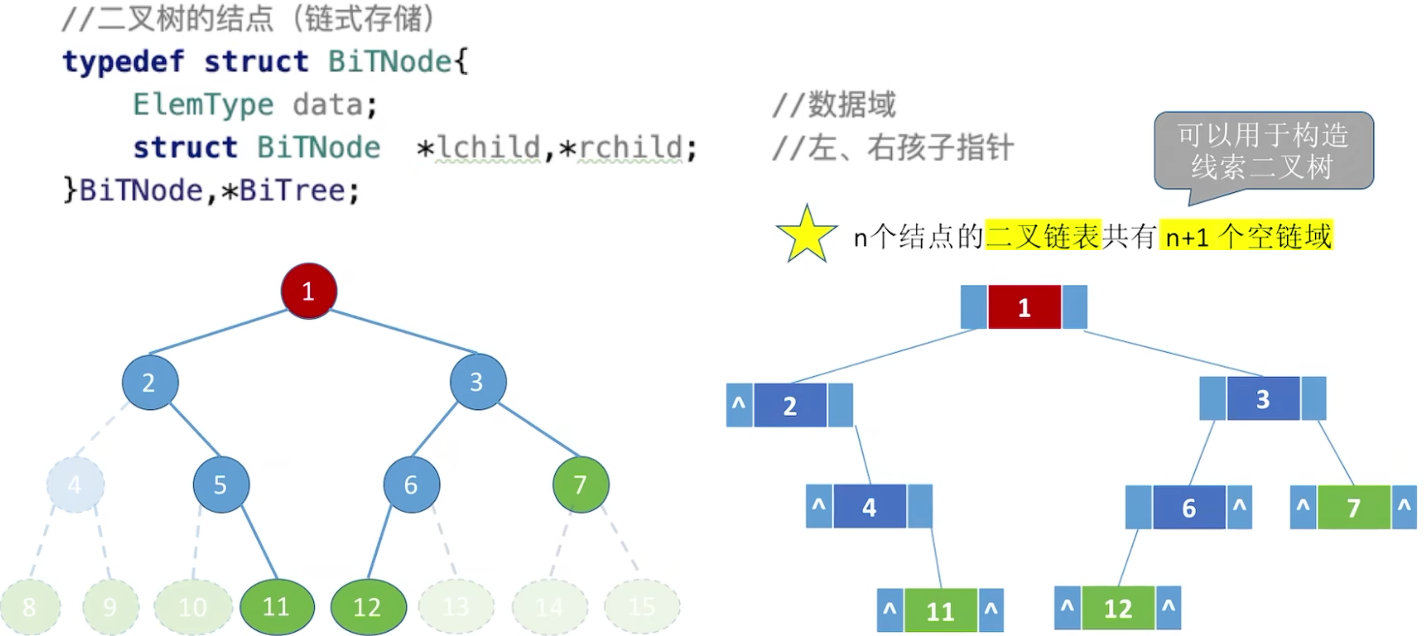
代码实现: 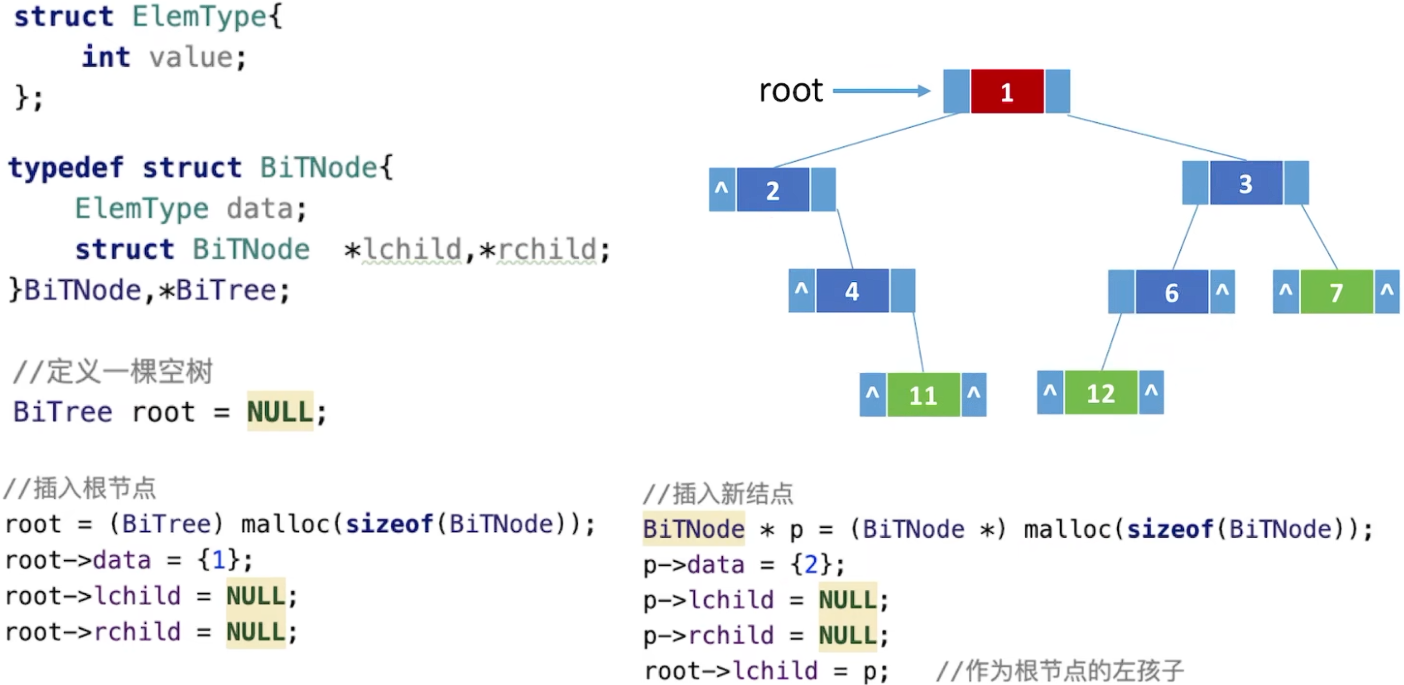
5.3 二叉树的遍历
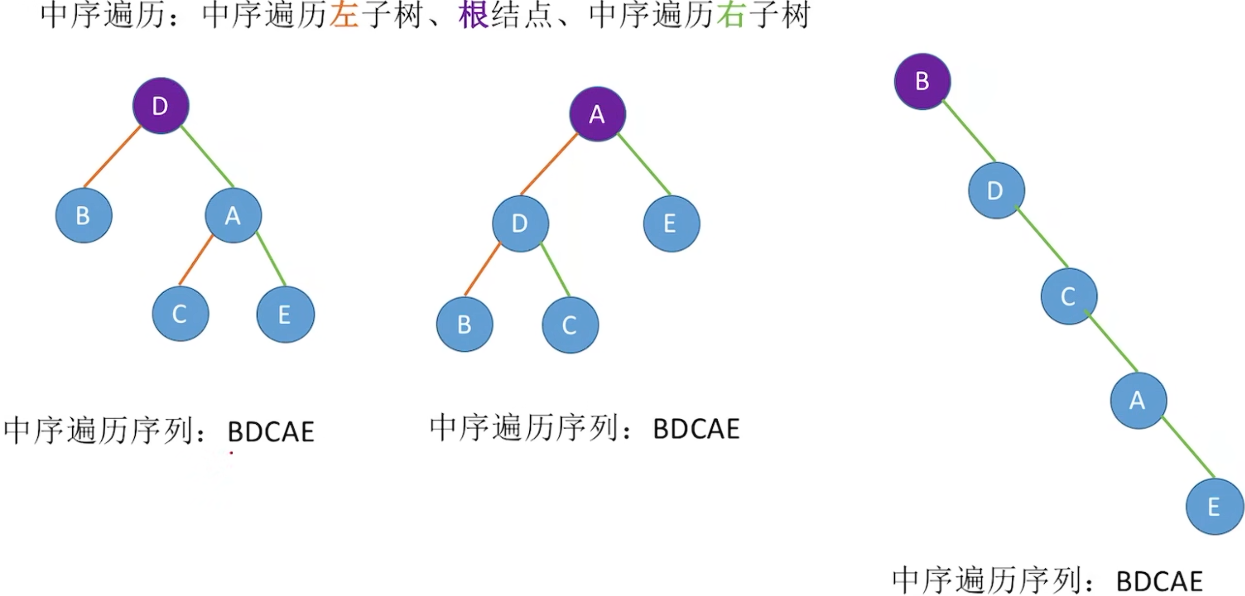
5.3.1 先中后序遍历(深度优先)

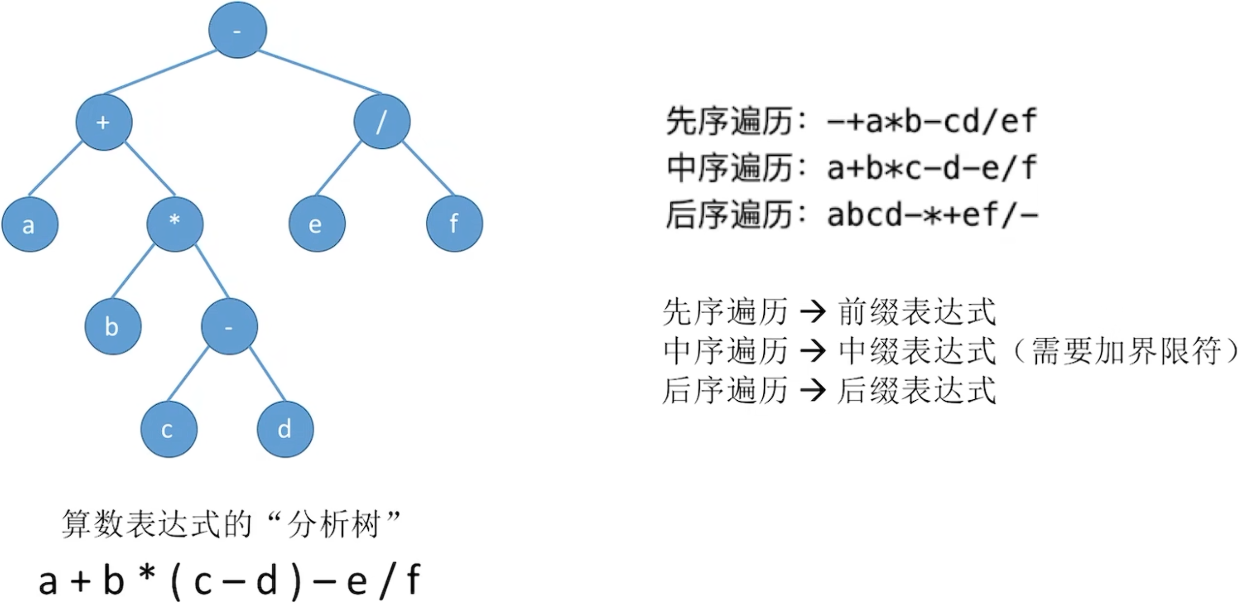
代码实现
调整visit()的位置就可以实现不同的算法: 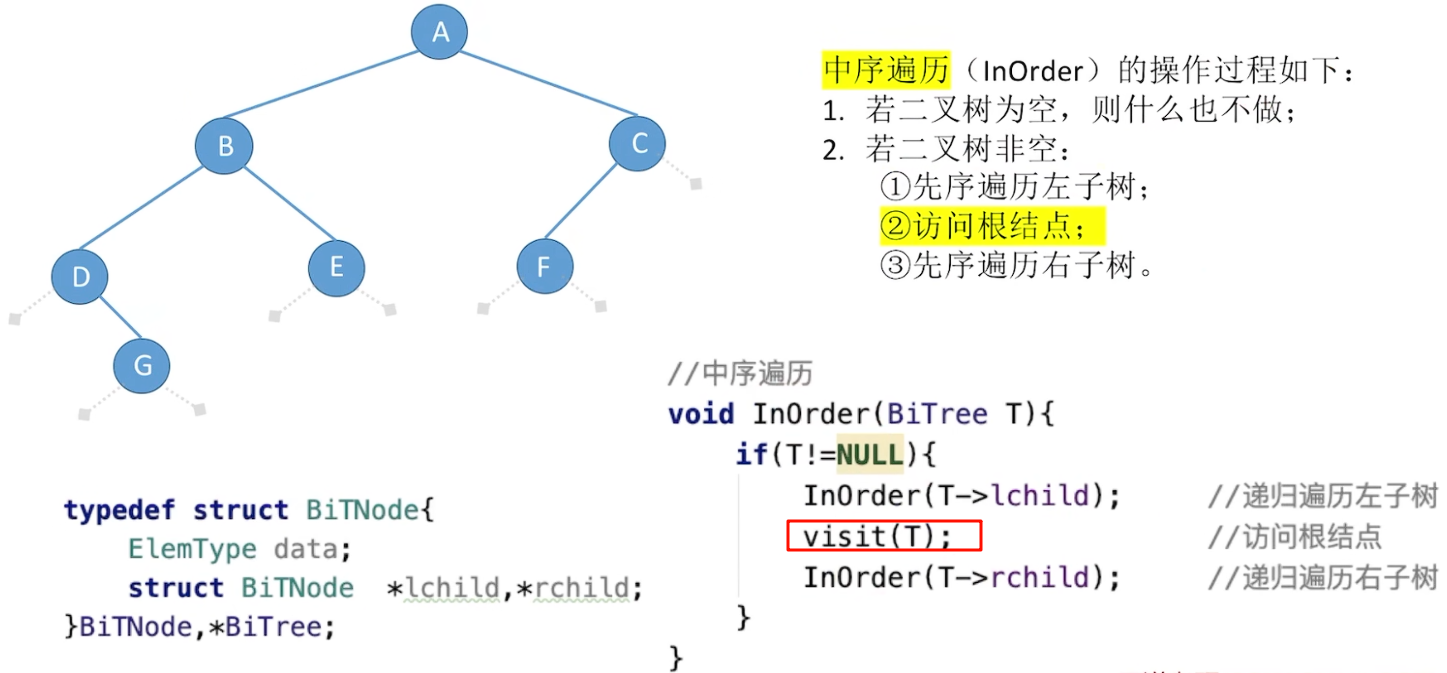
先序是第一次访问的结点,中序是第二次访问的结点: 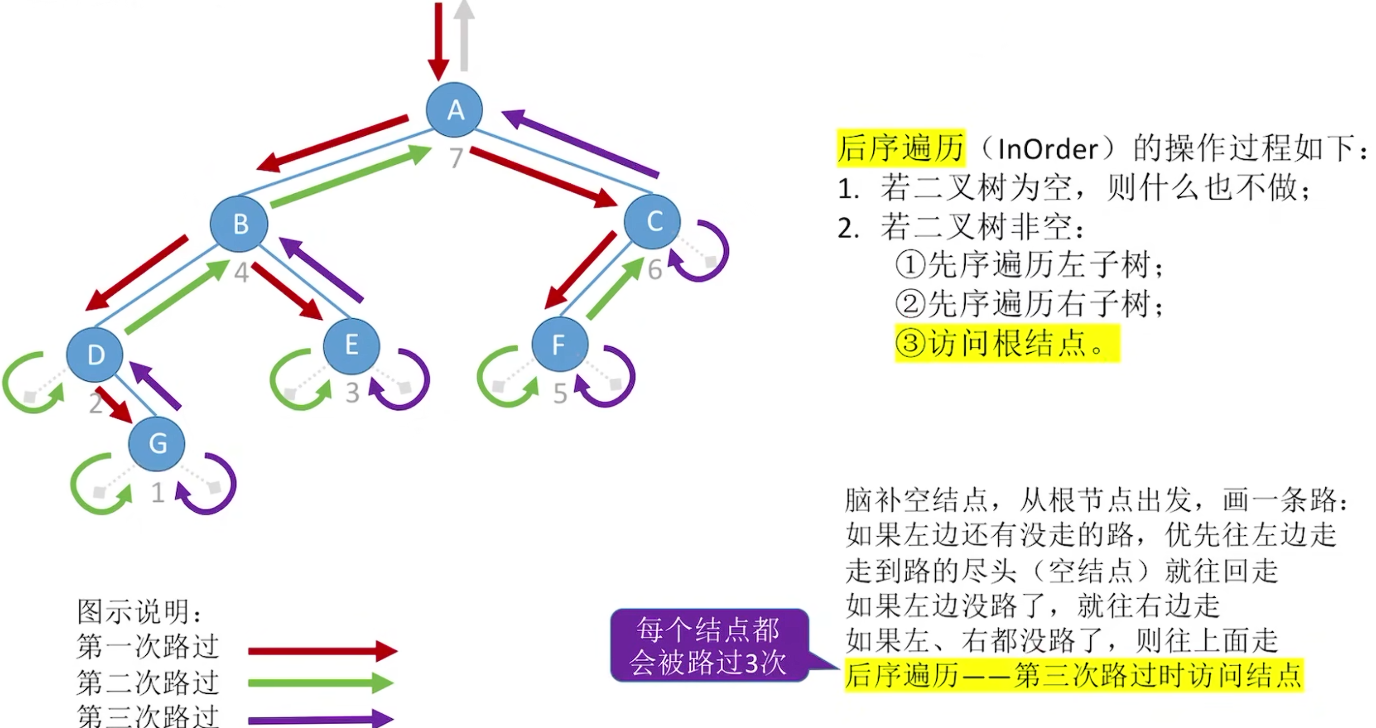
求深度

5.3.2 层次遍历(广度优先)
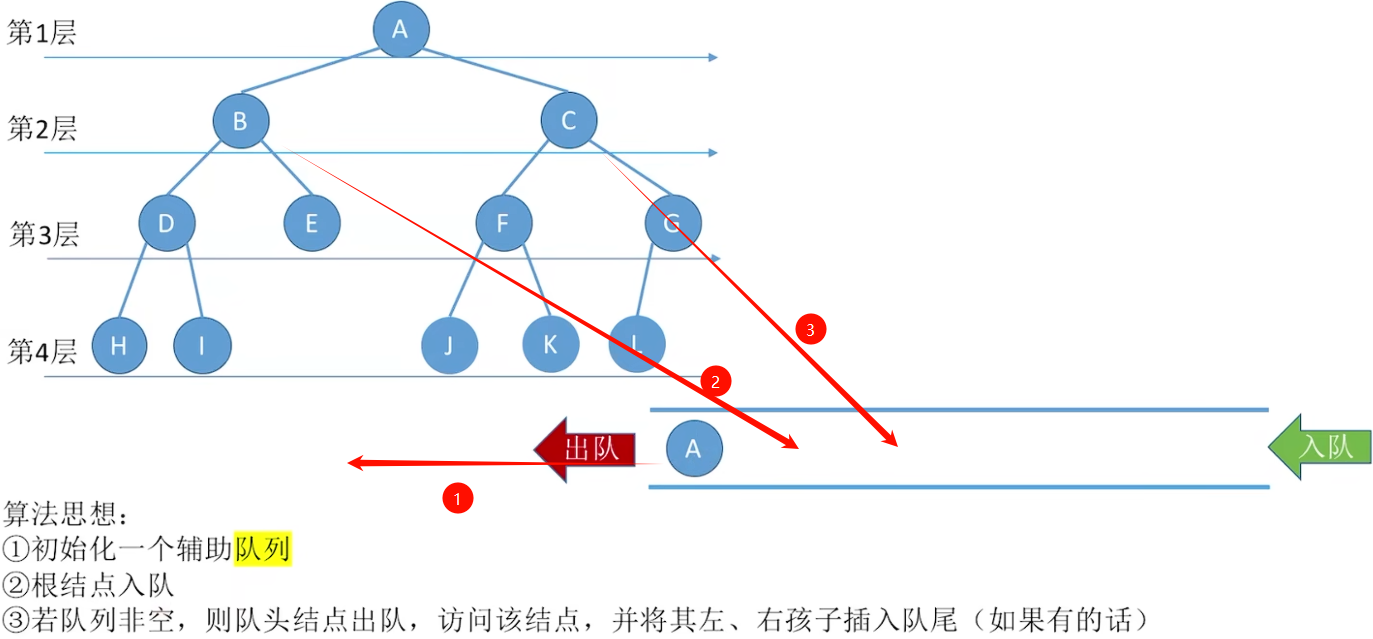
代码实现
 保存指针即可,可以减小空间消耗
保存指针即可,可以减小空间消耗
5.3.3 遍历序列构造二叉树
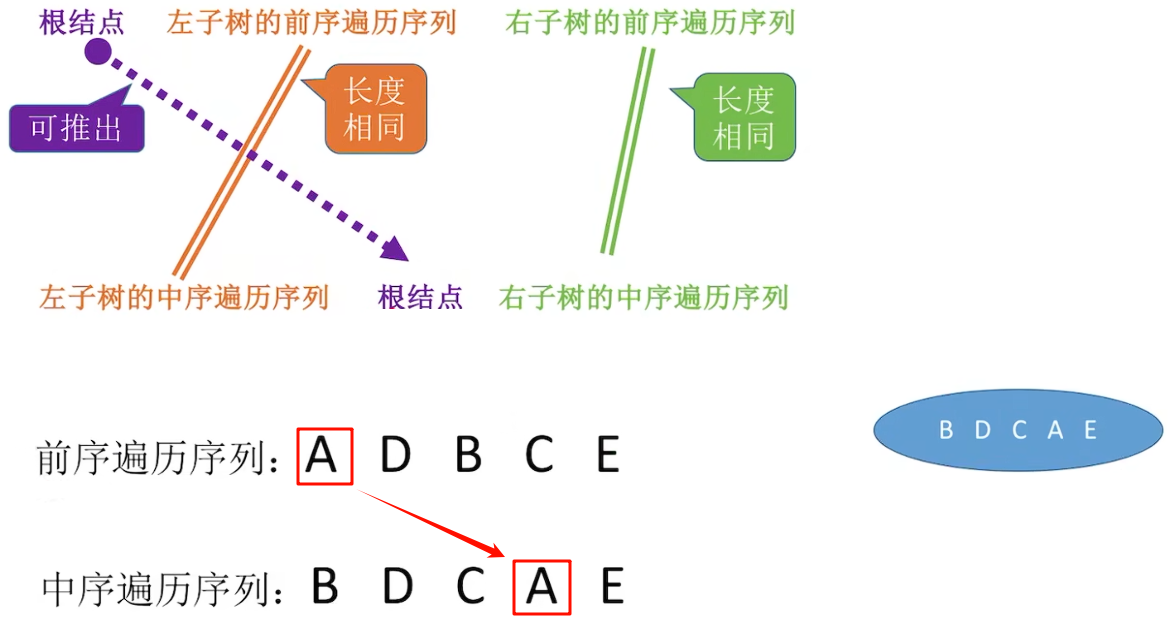
只依靠一种遍历序列不可能构造出唯一的二叉树结构,至少两种且必须包括中序:
先序与中序
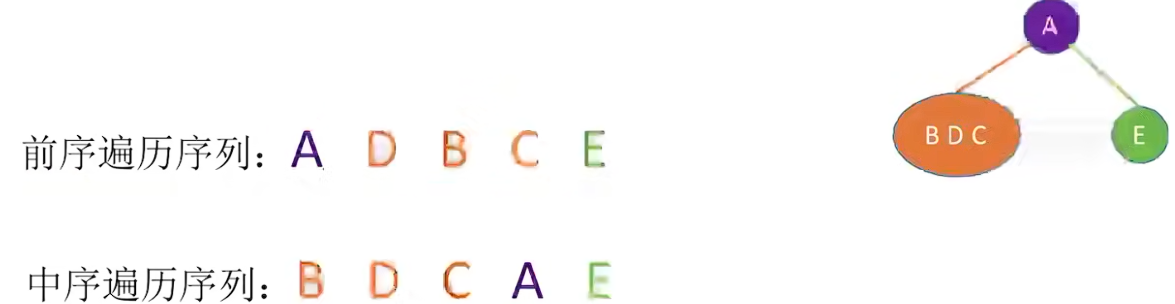
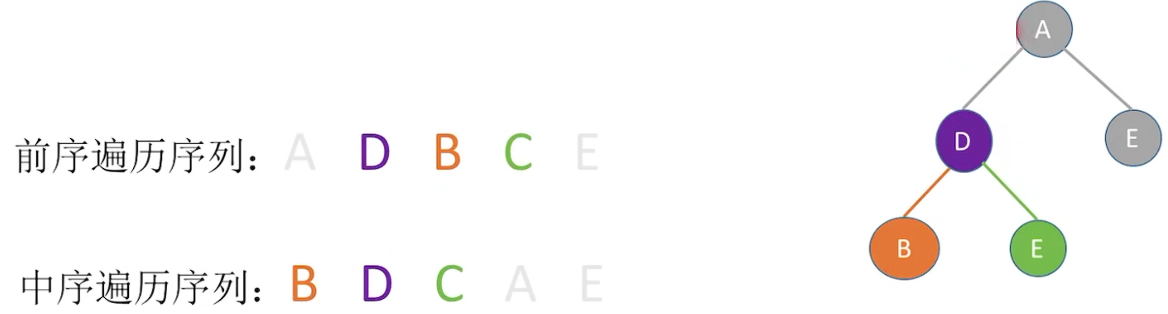
后序与中序
原理与先序一样
层次与中序
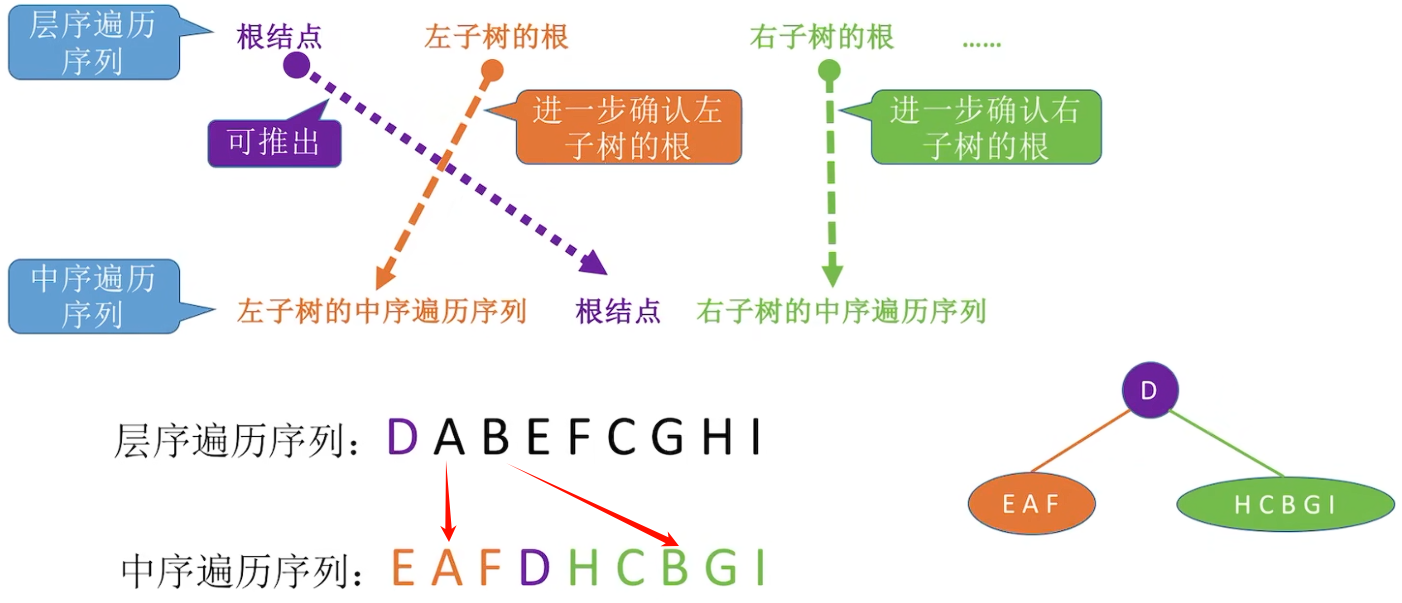
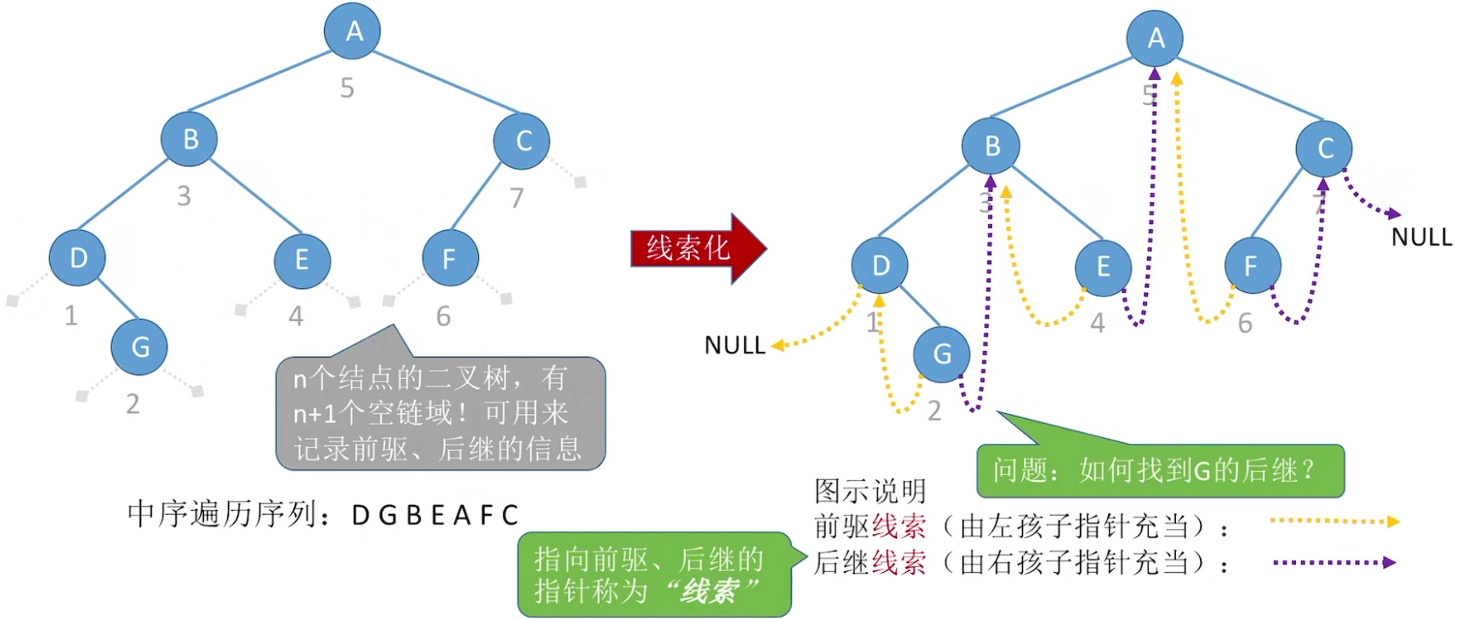
5.3.4 线索二叉树
在普通的二叉树中去通过一个非根结点去遍历或寻找它的前驱与后继是很困难的
中序线索二叉树
 寻找中序后继next:
寻找中序后继next: 
寻找中序前驱pre: 
先序线索二叉树
寻找先序后继next: 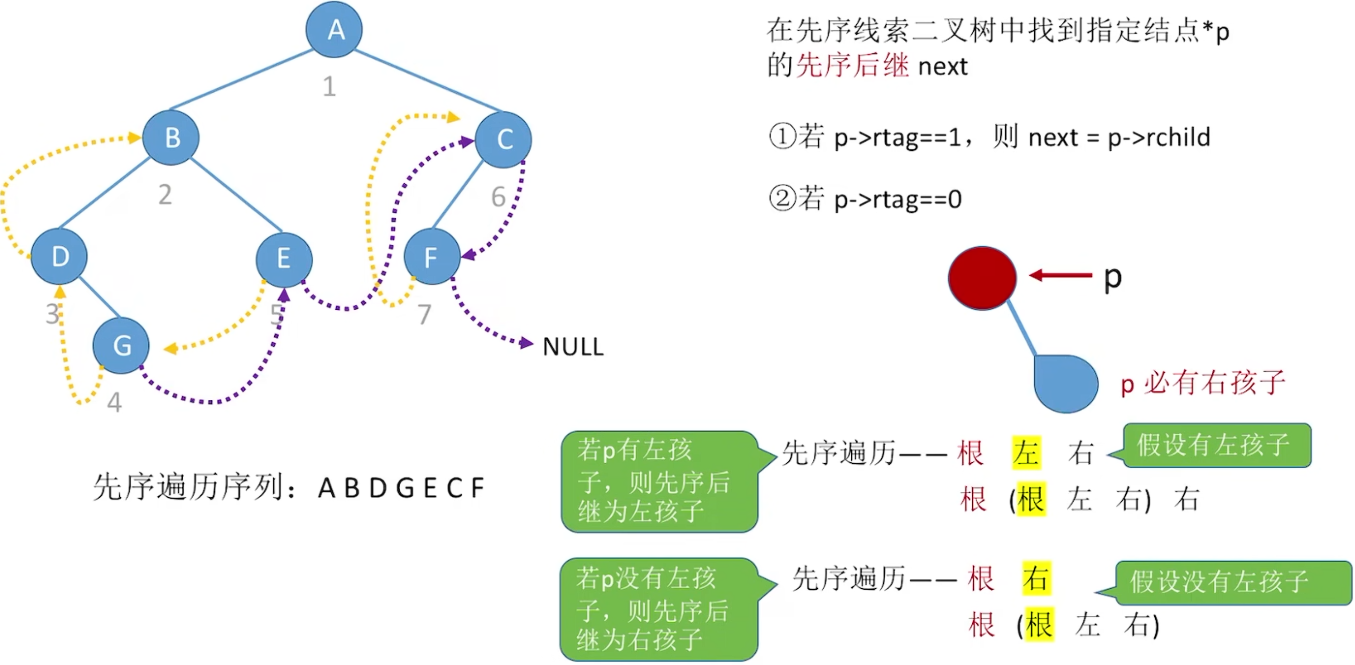
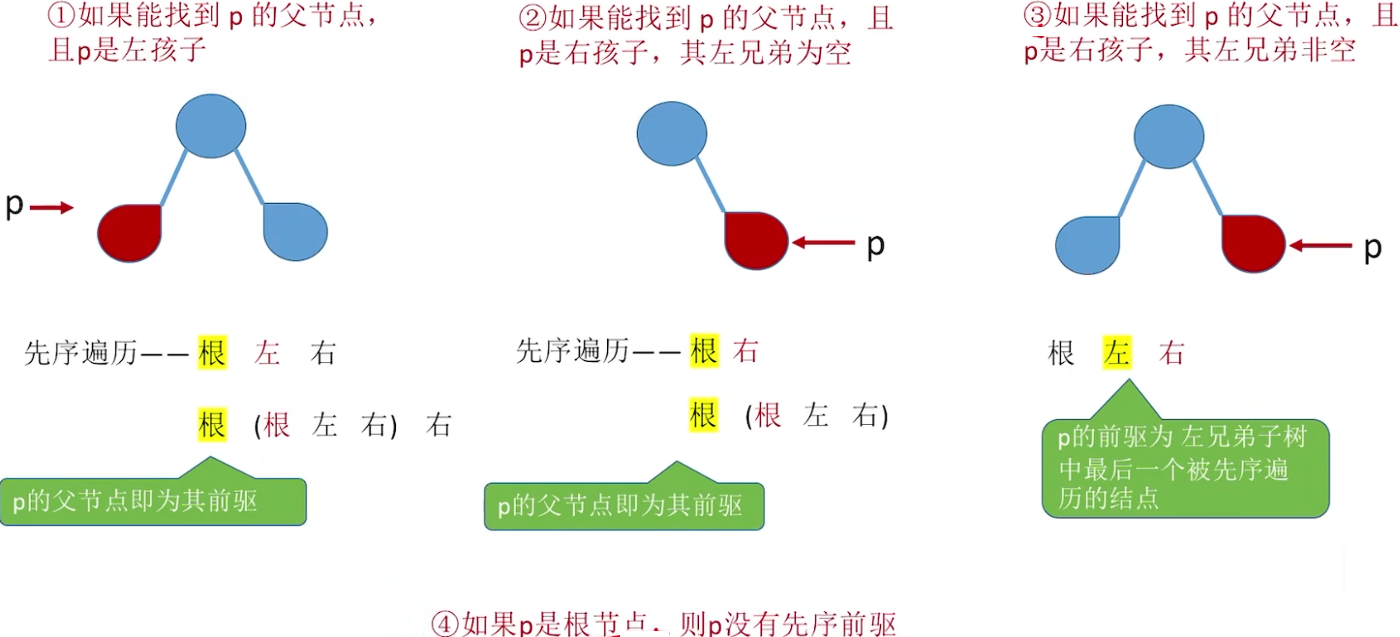
寻找先序前驱pre: 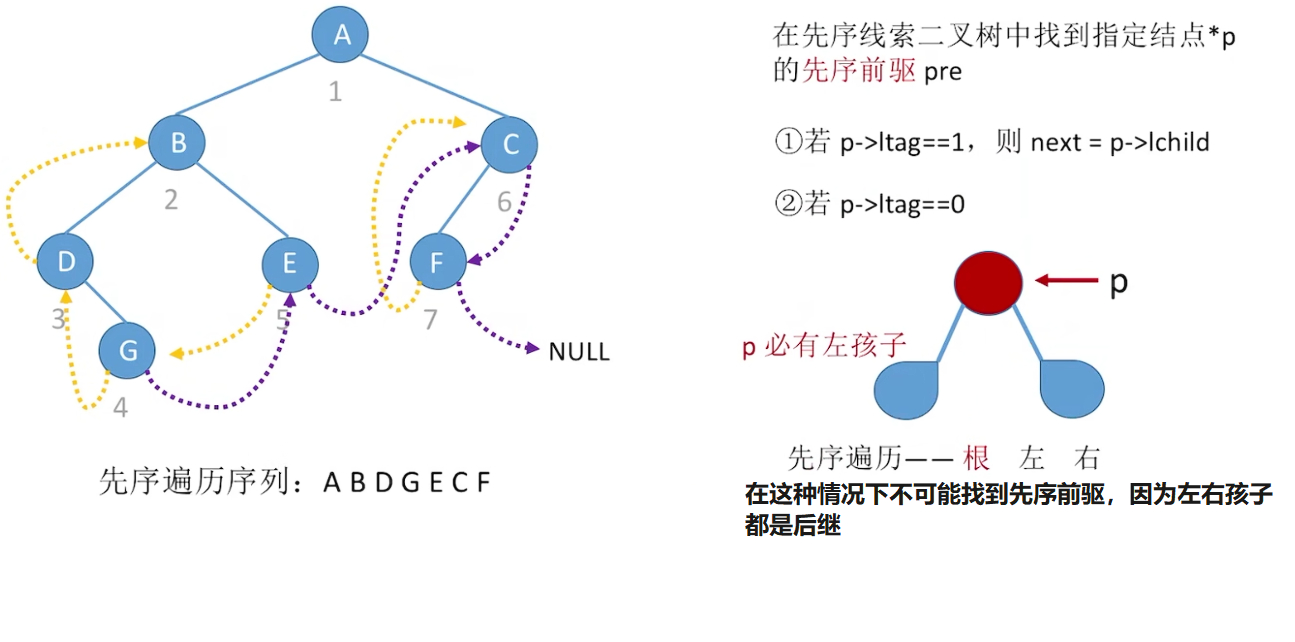
- 如果使用三叉链表(有指向父节点的指针)
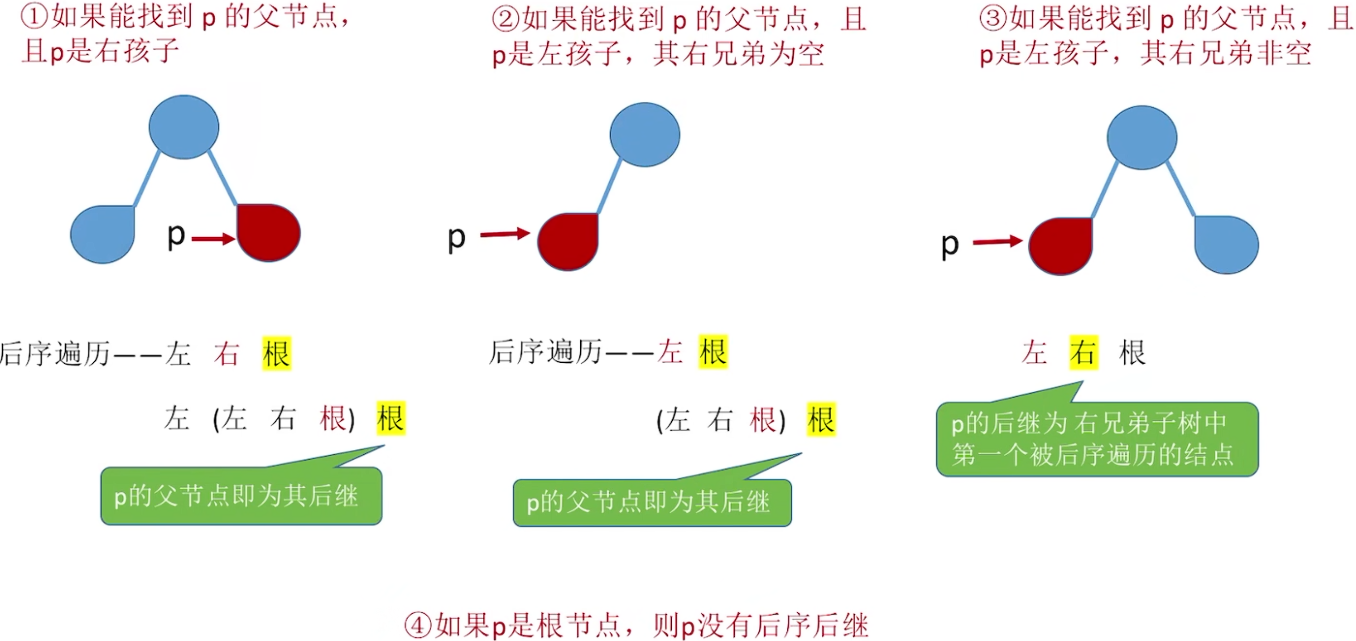
后序线索二叉树
后序前驱: 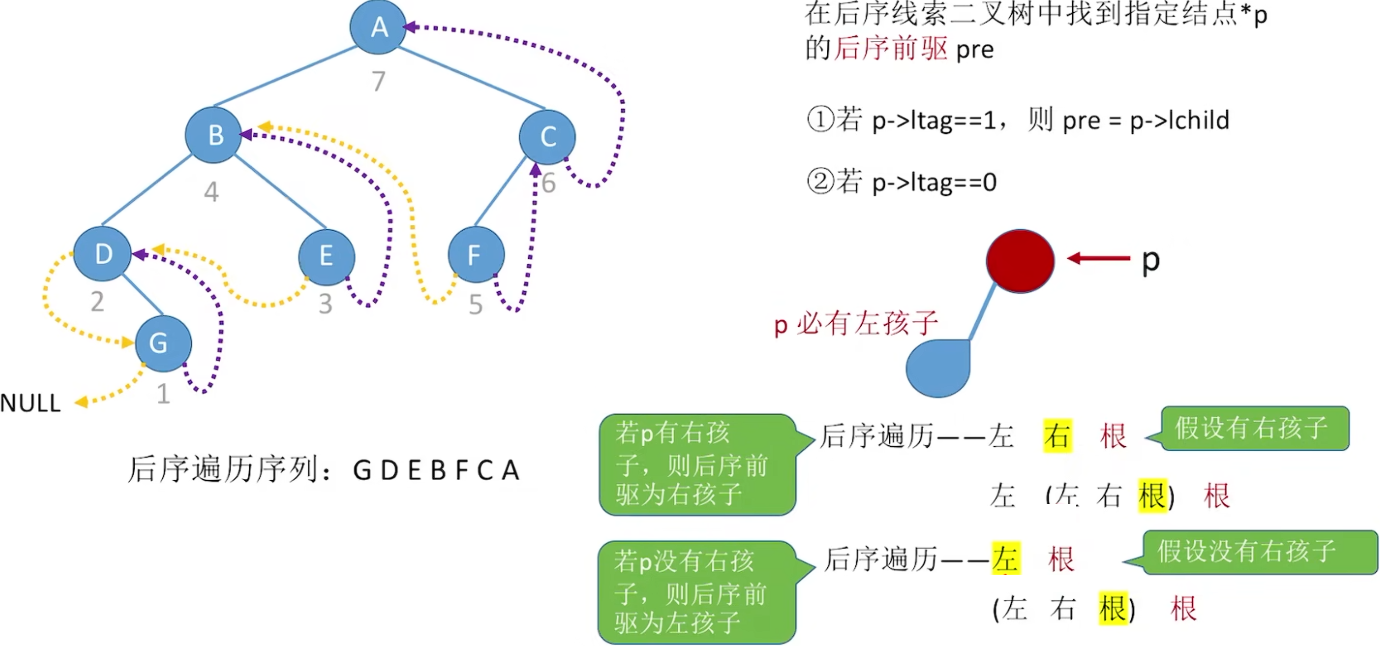 后序后继:
后序后继: 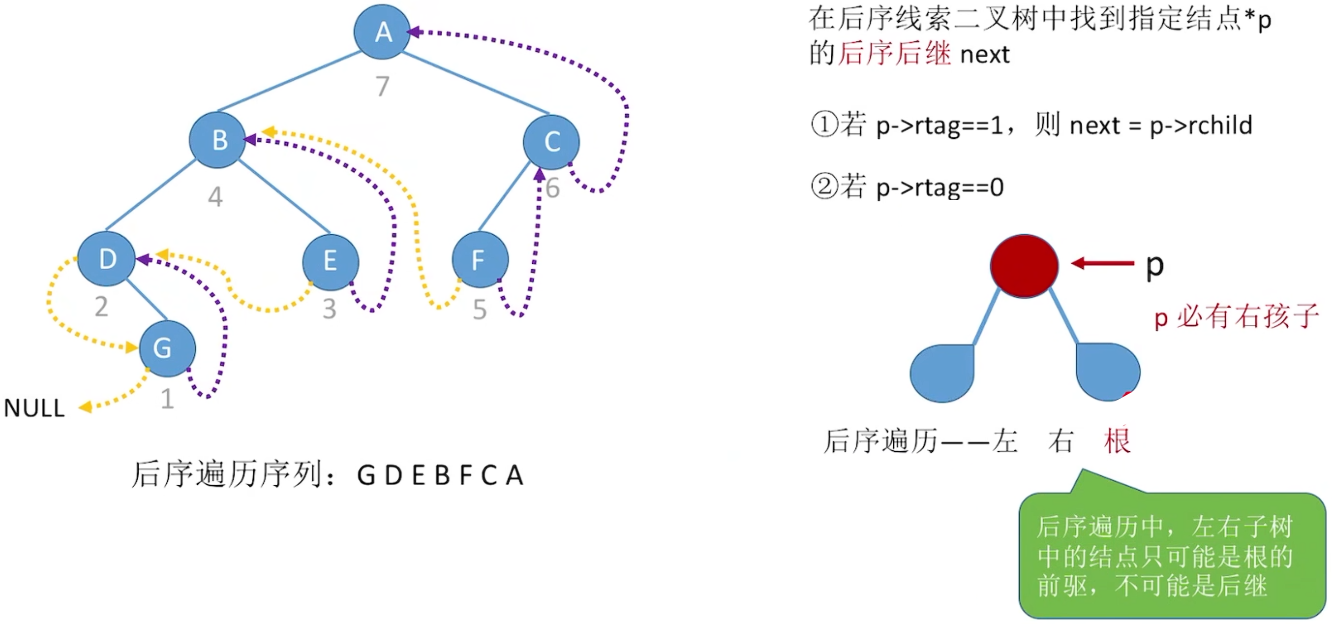
 总结上述三种:
总结上述三种: 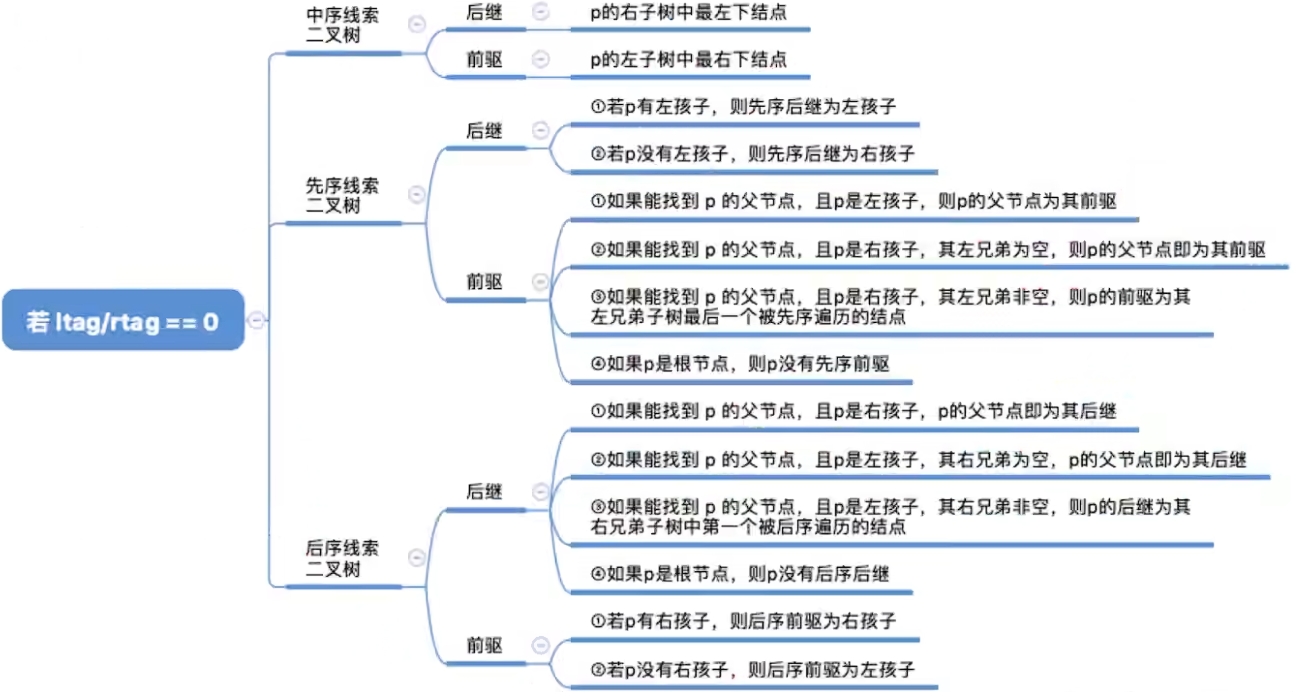
存储结构
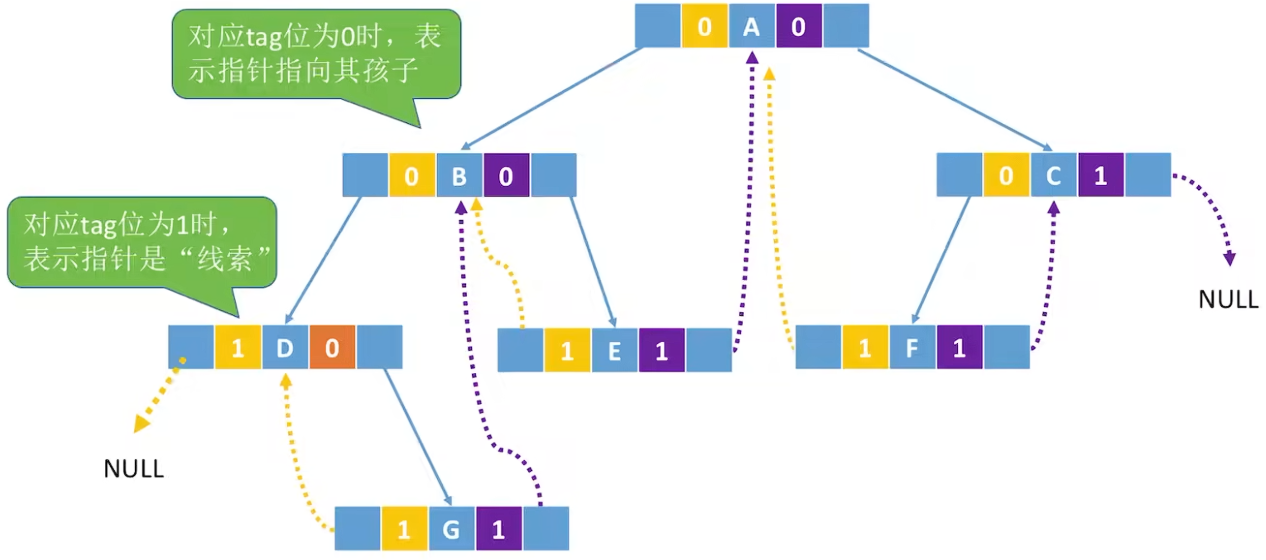
代码实现
中序线索化: 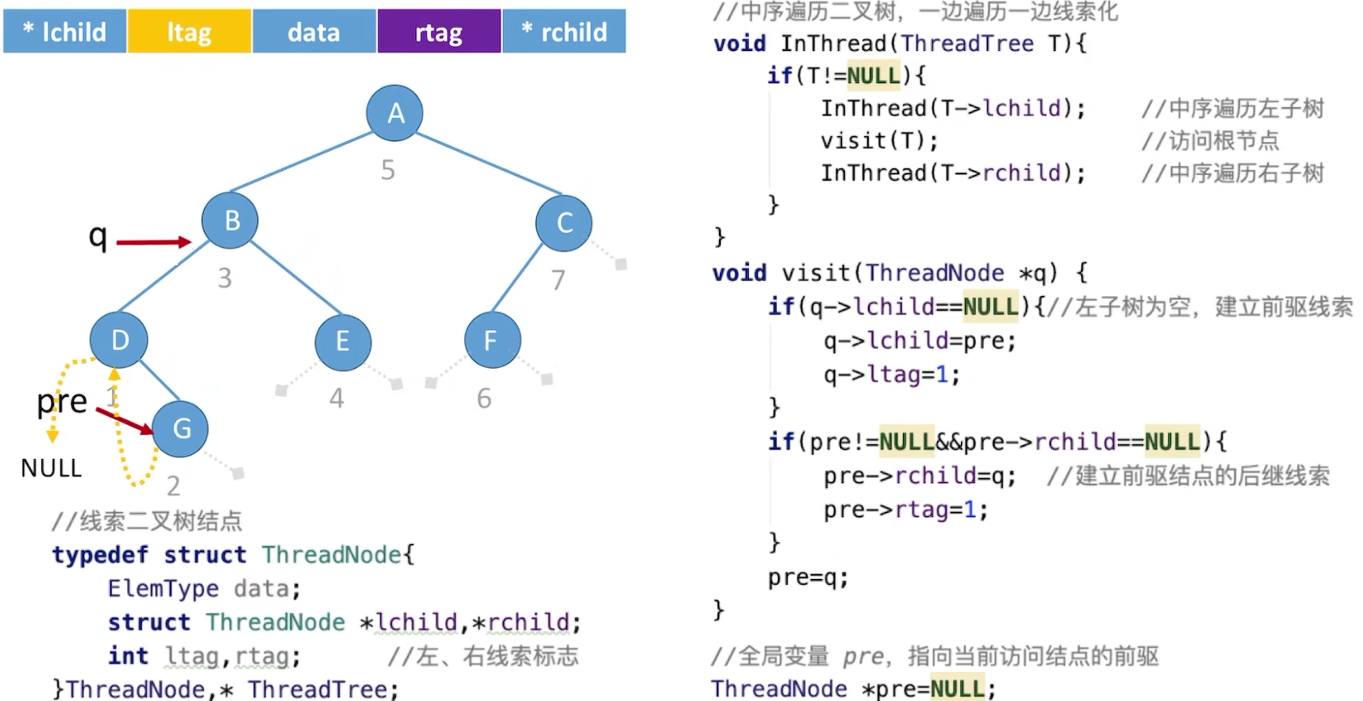
另一种实现方式:  前序和后序调整visit()的代码顺序即可,但是注意在先序线索化的时候要判断某个结点的左孩子是否为线索化的前驱,这样会有循环问题,后序没有这个问题。
前序和后序调整visit()的代码顺序即可,但是注意在先序线索化的时候要判断某个结点的左孩子是否为线索化的前驱,这样会有循环问题,后序没有这个问题。 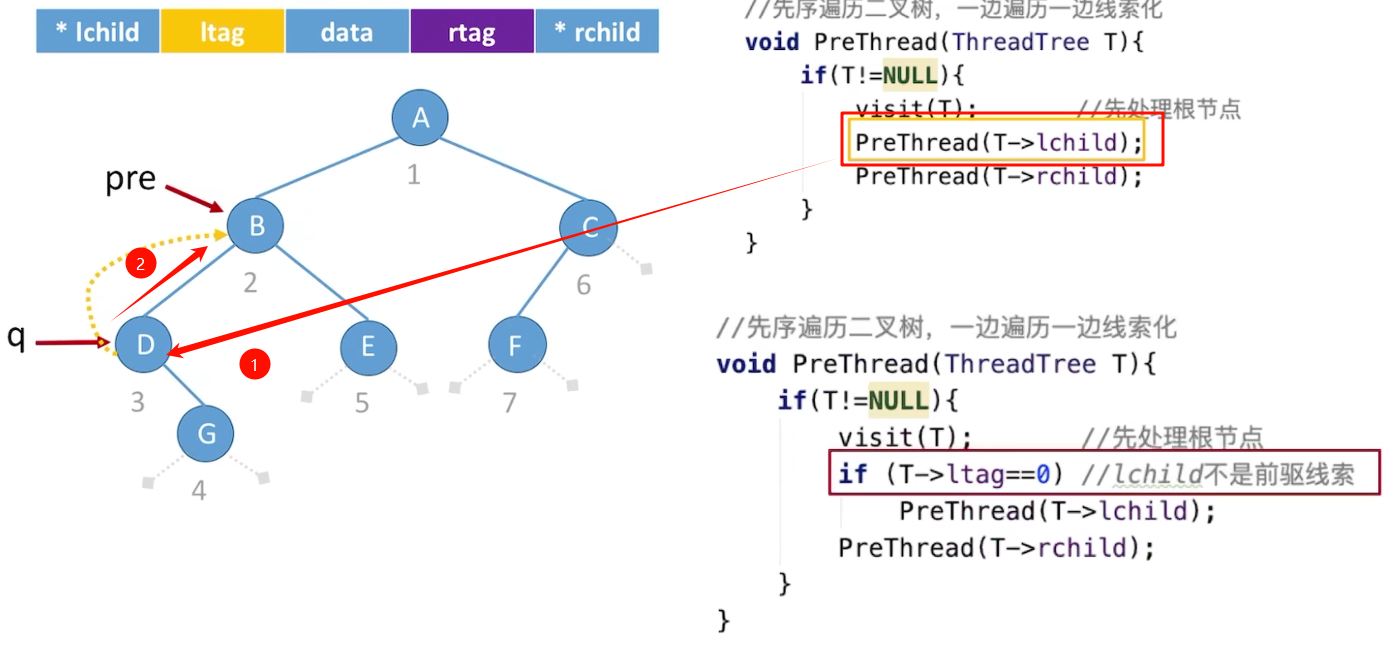 无论哪种线索化,都要注意最后一个结点的右孩子和rtag的处理
无论哪种线索化,都要注意最后一个结点的右孩子和rtag的处理
5.4 树的结构
5.4.1 树的存储结构
双亲表示法(顺序存储)
树中每个非跟结点都有一个根结点。找父节点方便,但是找孩子结点困难,需要遍历数组。同时这种方式可以表示森林 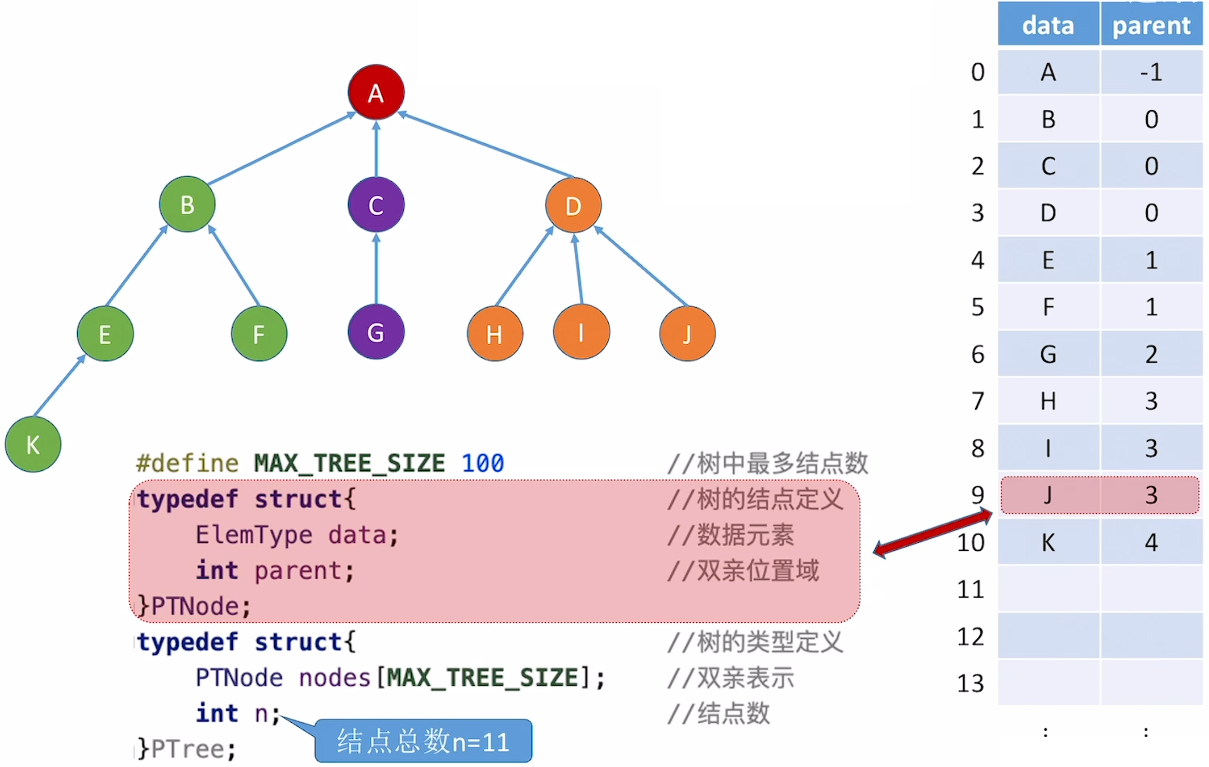
孩子表示法(顺序+链式存储)
便于找孩子,找父节点困难。可以表示森林,但要记录多个跟结点。 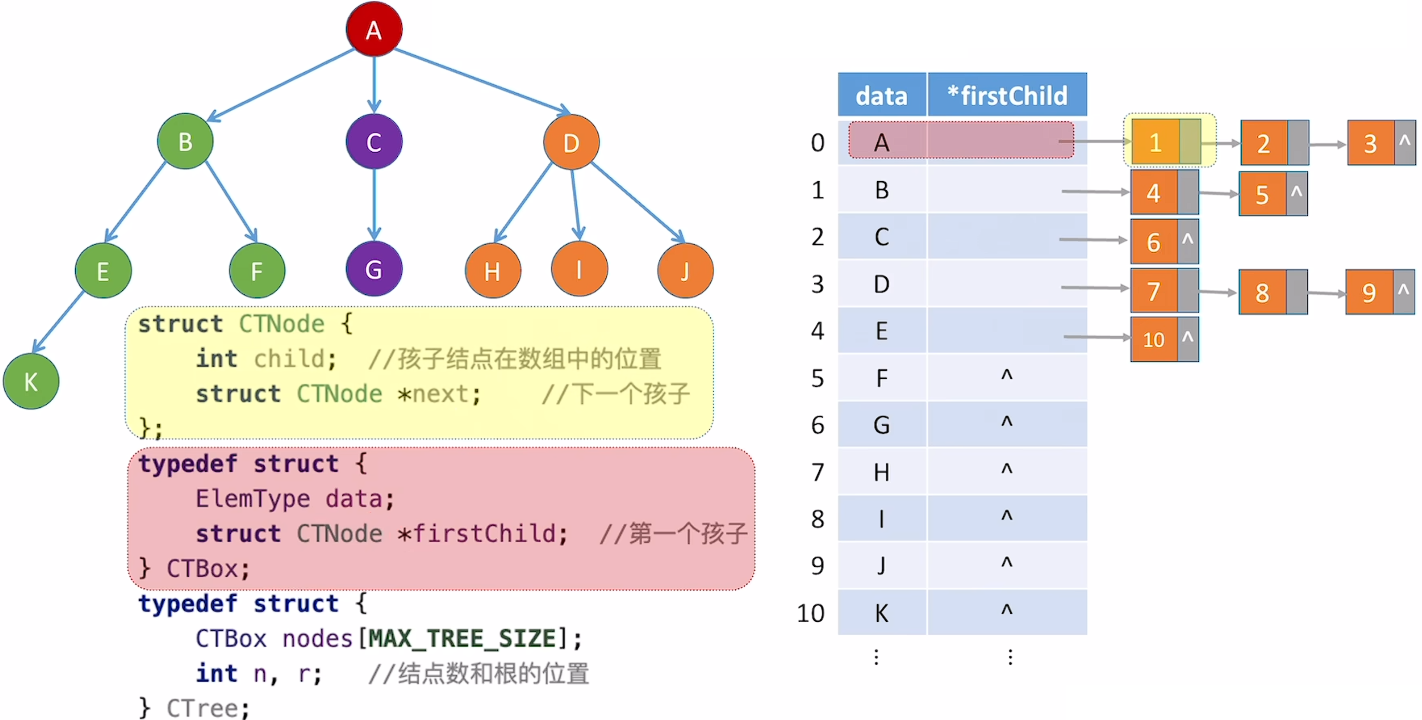
孩子兄弟表示法(链式存储)
也可以表示森林,森林中每棵树视为兄弟关系 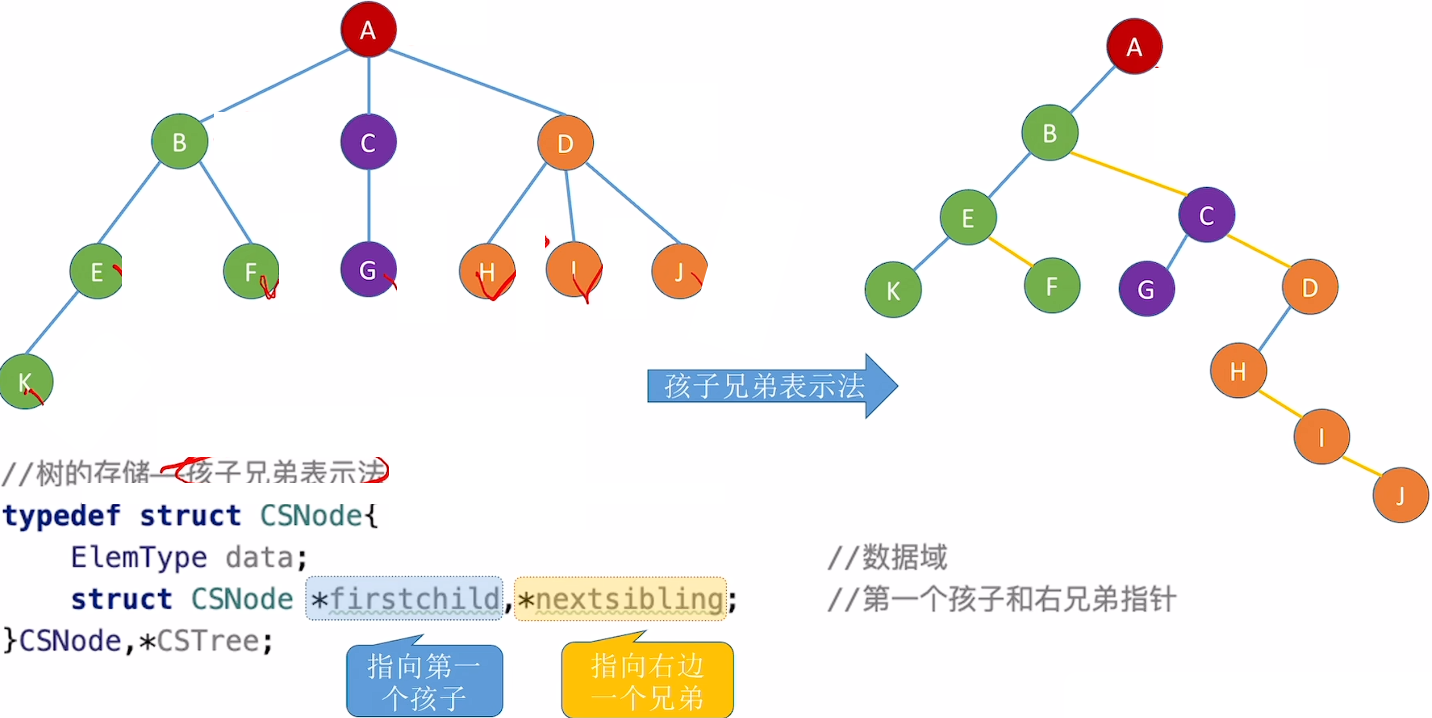
5.4.2 树、森林二叉树之间的转换
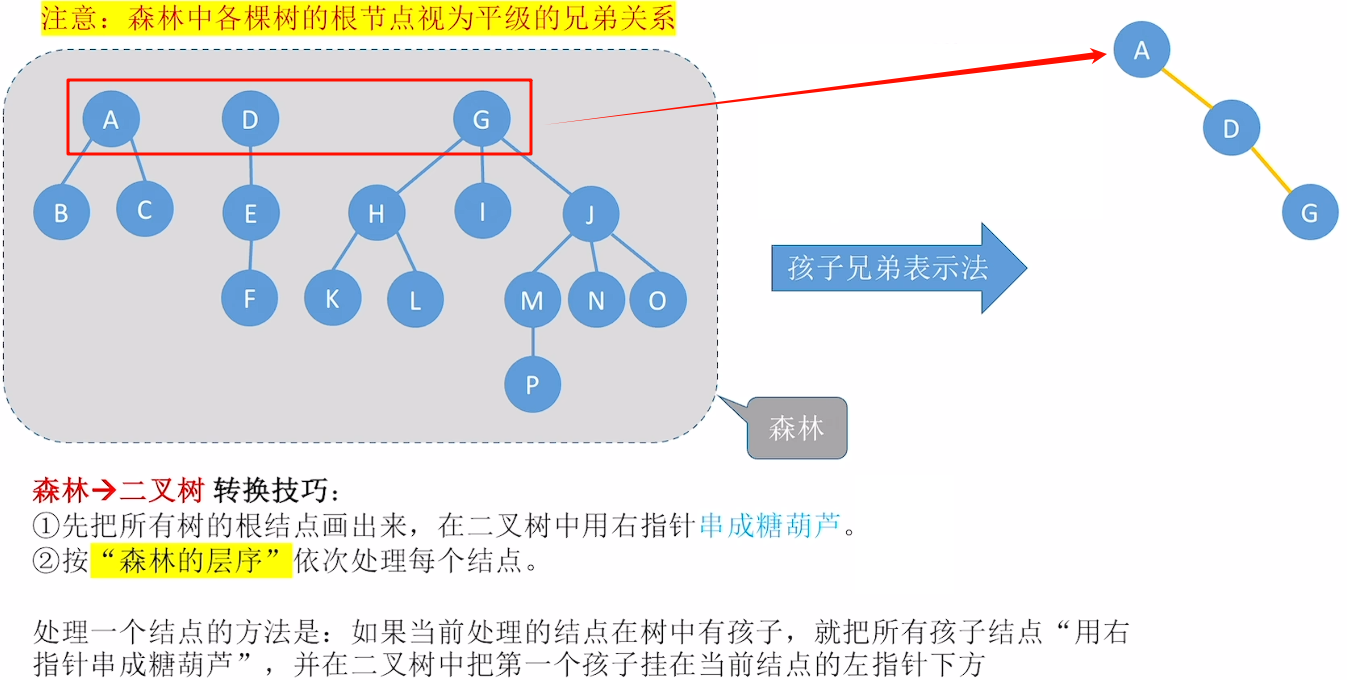
树、森林转化为二叉树
使用孩子兄弟表示法 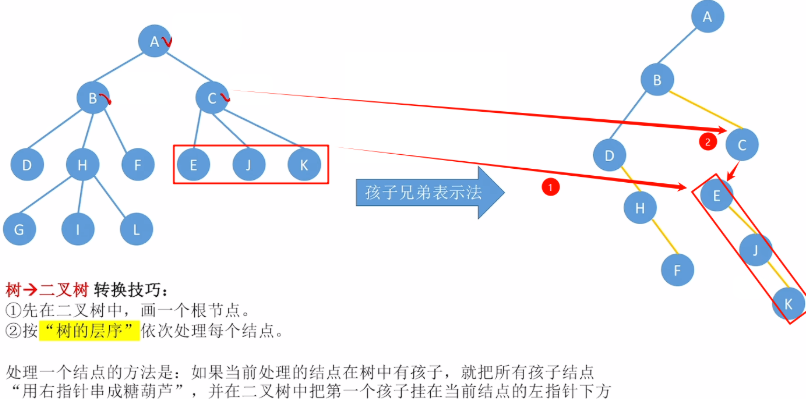
二叉树转化为树、森林
树: 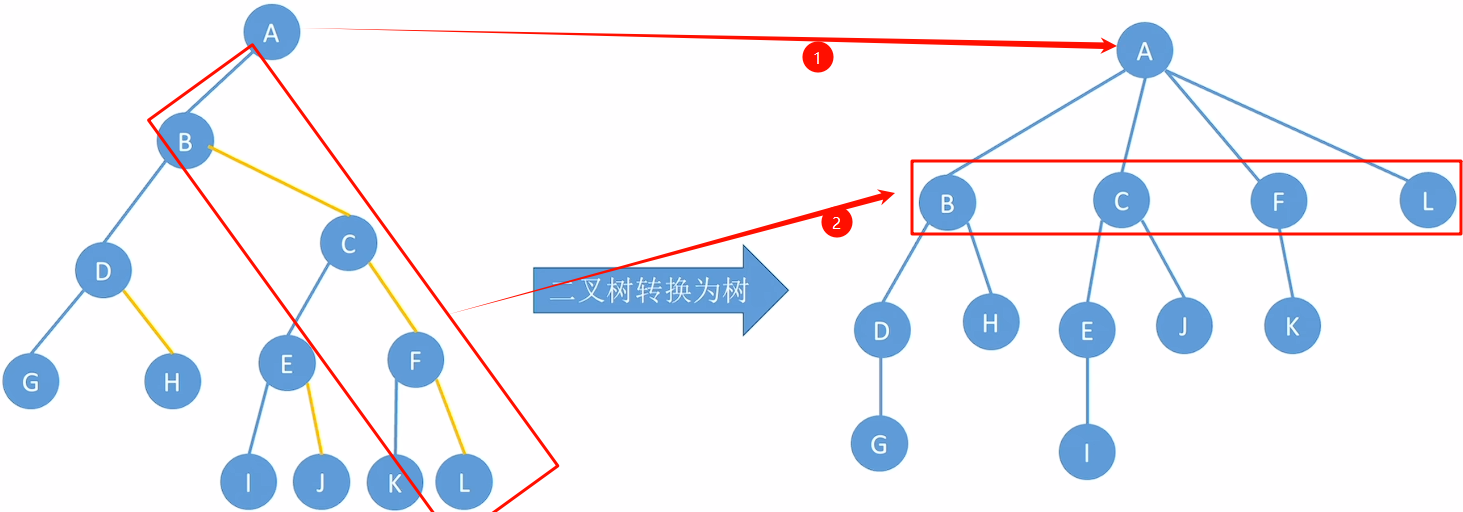
森林: 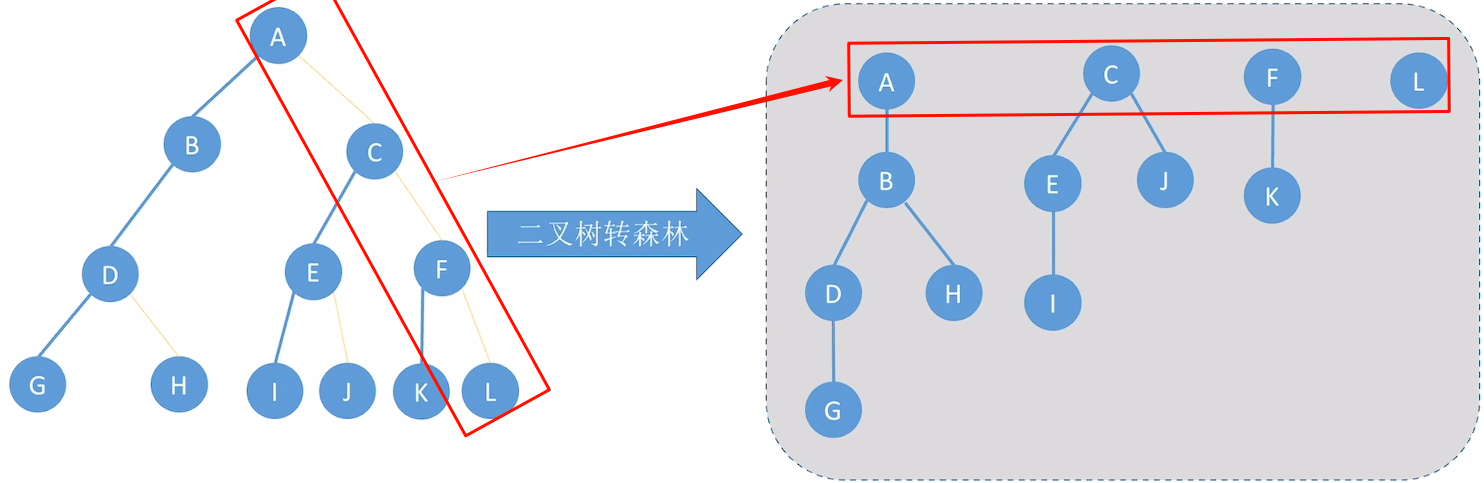
5.4.3 树与森林的遍历
树的遍历
先根(深度): 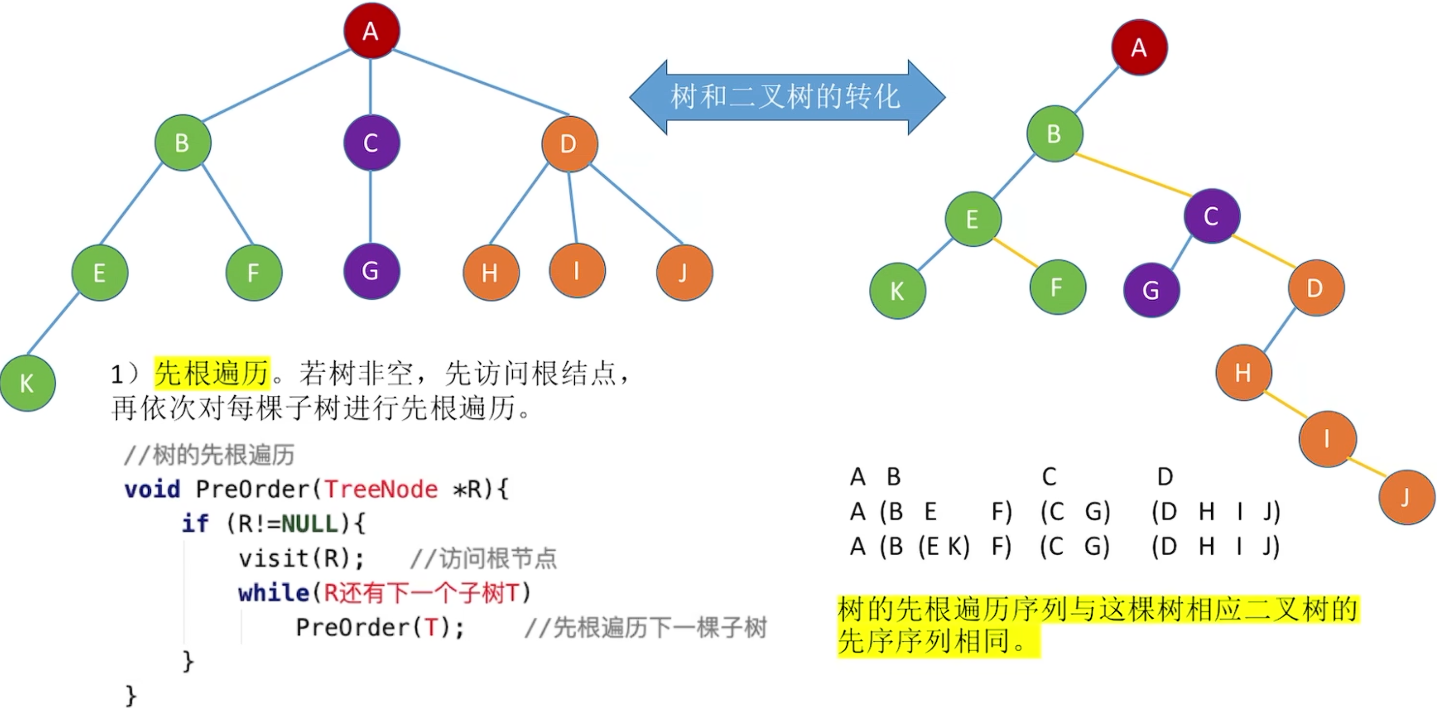
后根(深度): 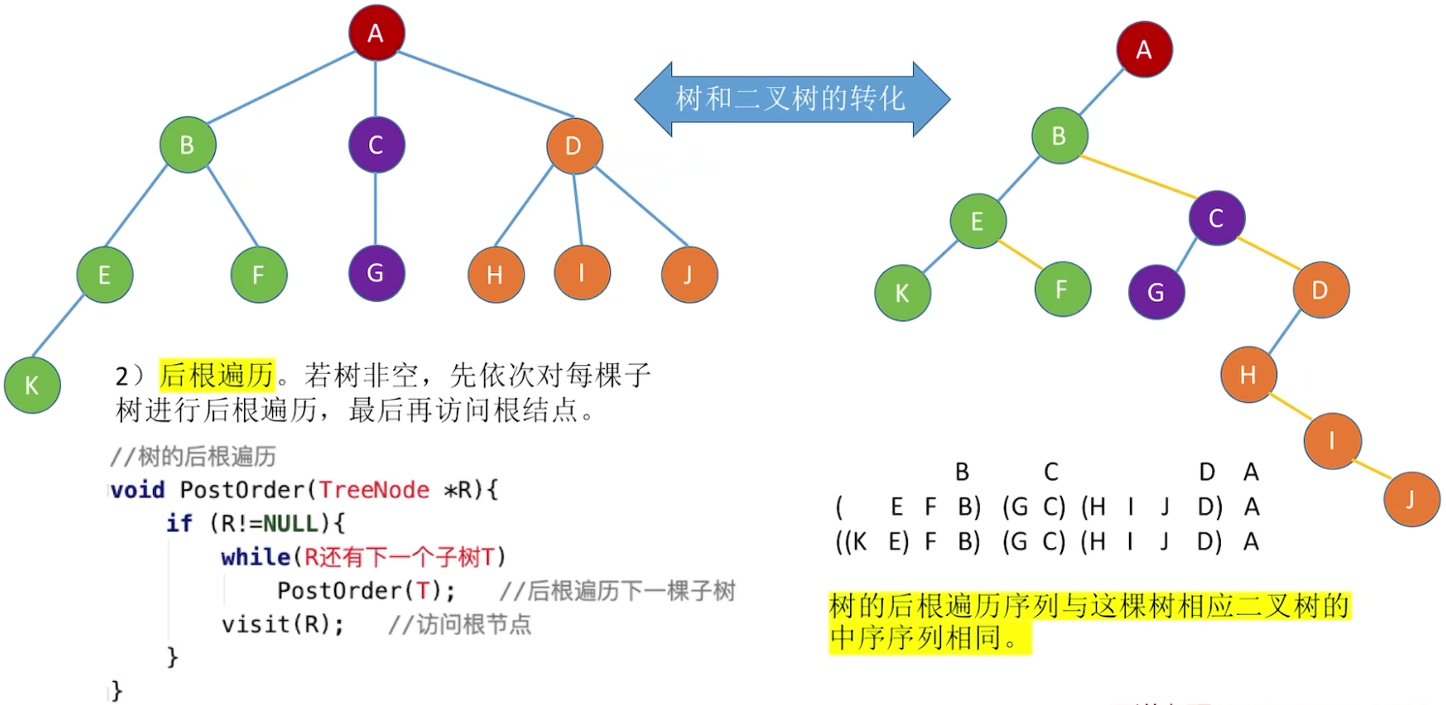
层次(深度): 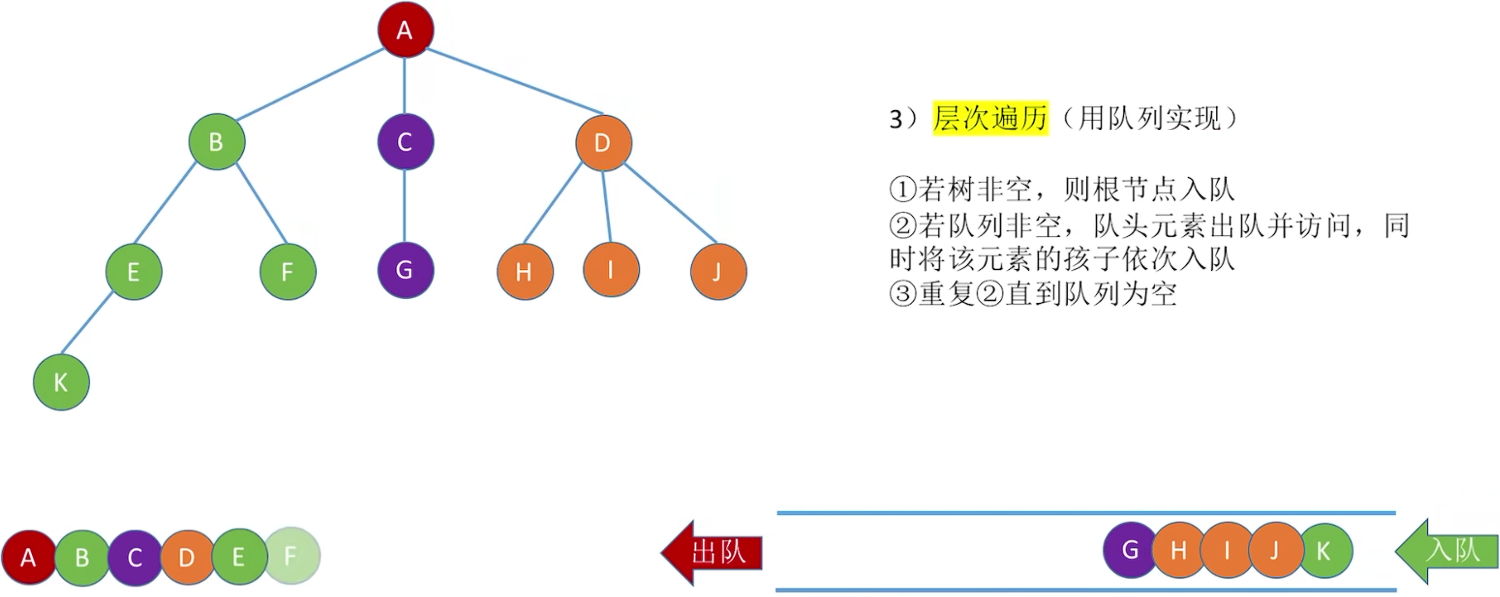
森林的遍历
先序:等同于对每棵子树做先根遍历,也等同于对森林转化的二叉树的先序遍历 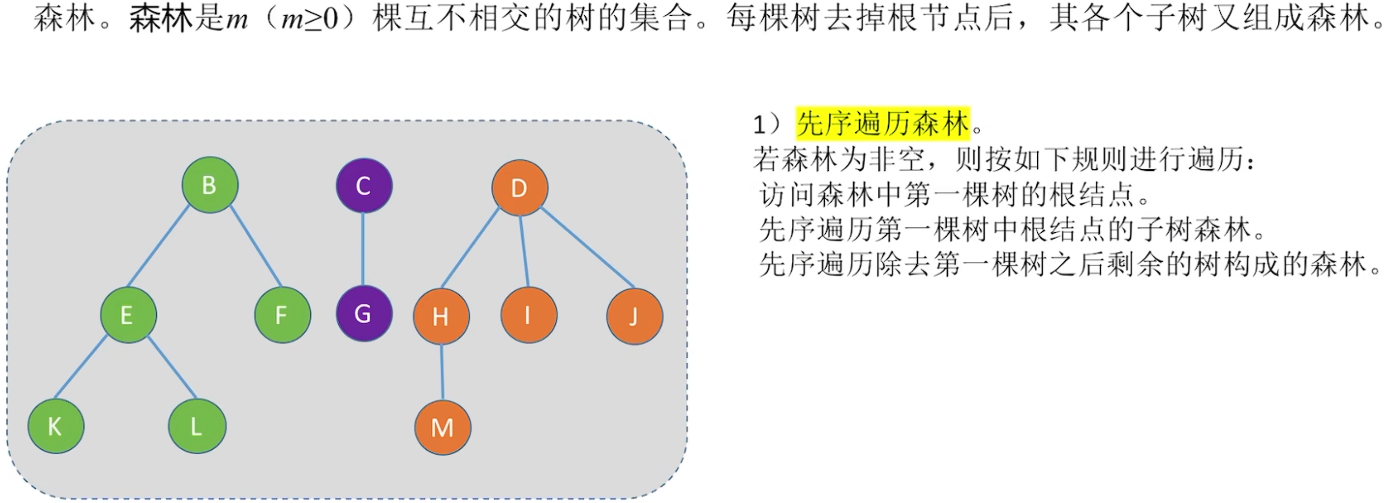
中序:等同于对每棵子树做后根遍历,也等同于对森林转化的二叉树的中序遍历 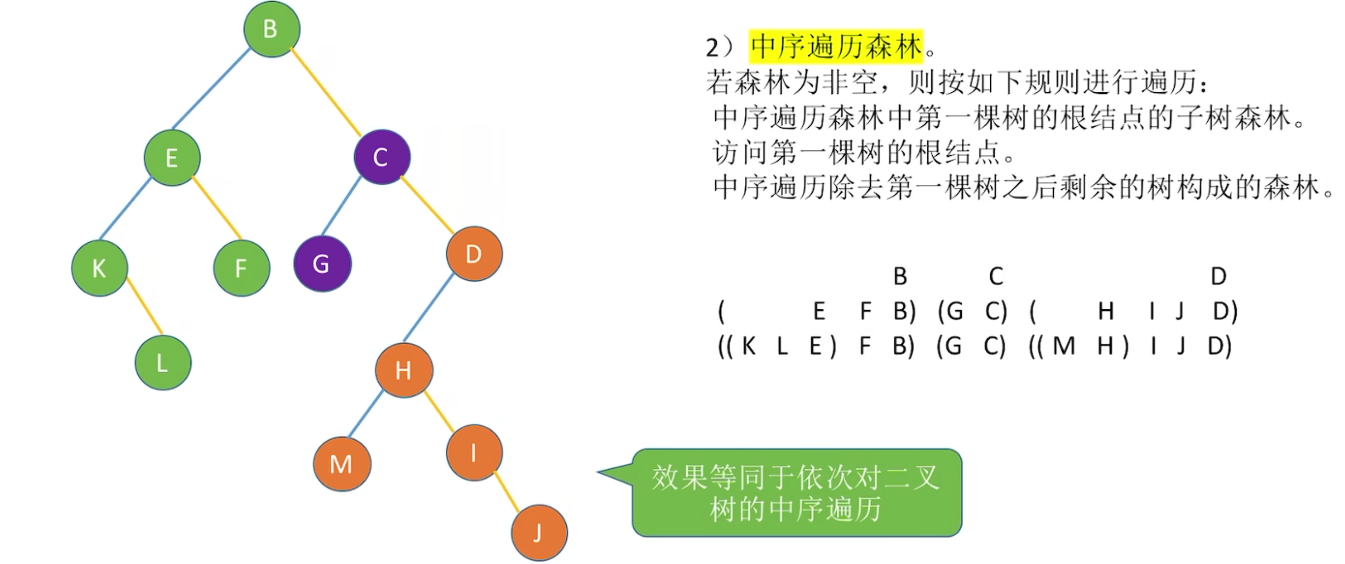
5.5 树的应用
5.5.1 哈夫曼树
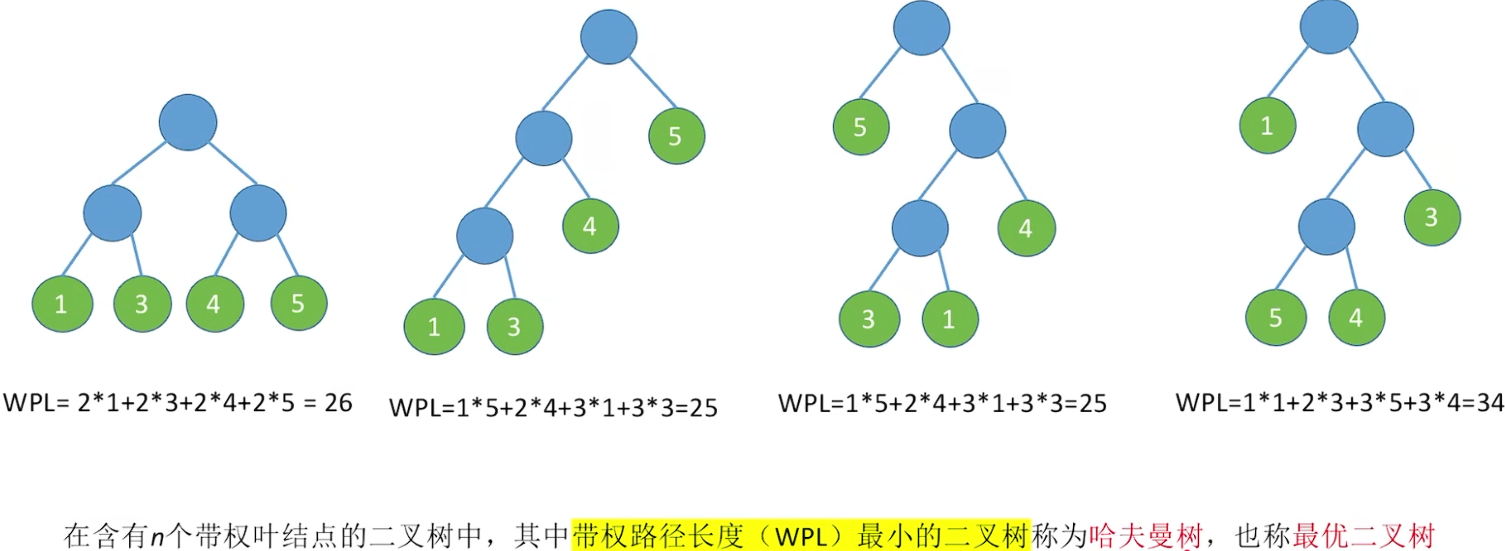
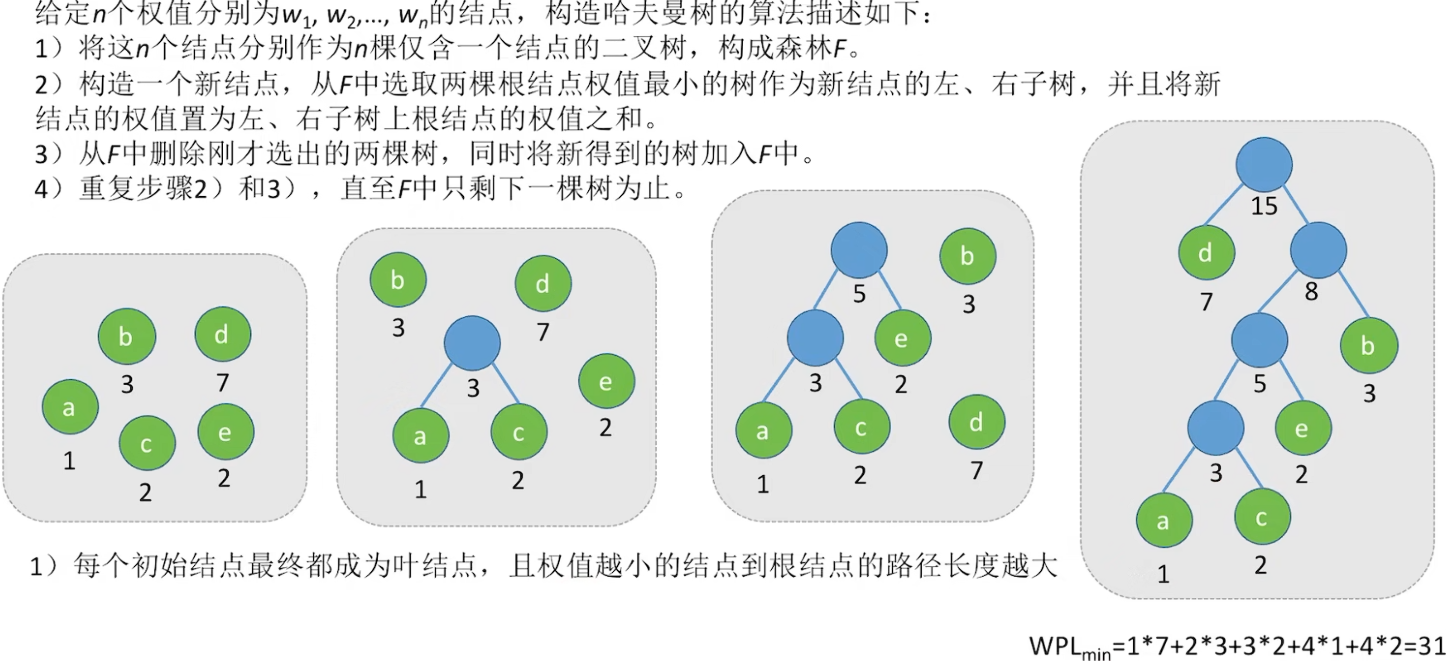
带权路径长度(WPL)最小的二叉树,可能不唯一 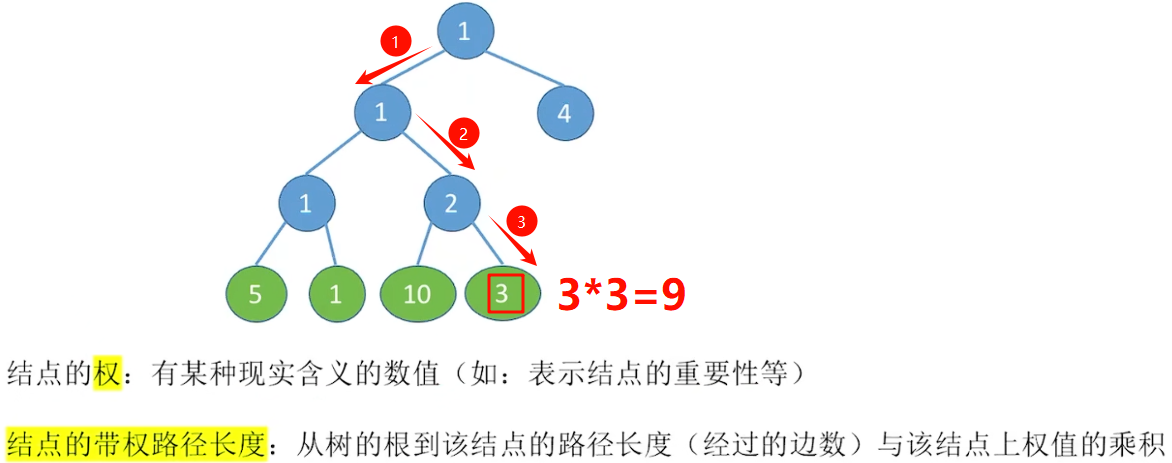
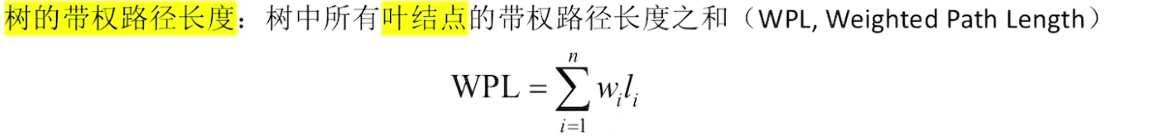
构造哈夫曼树

哈夫曼编码(可变长编码)
对于使用固定长度编码的树,所传递的信息的效率较低,也就是WPL较大,可以使用哈夫曼树来优化(编码结果可能不唯一),并且解码不会有歧义(前缀编码): 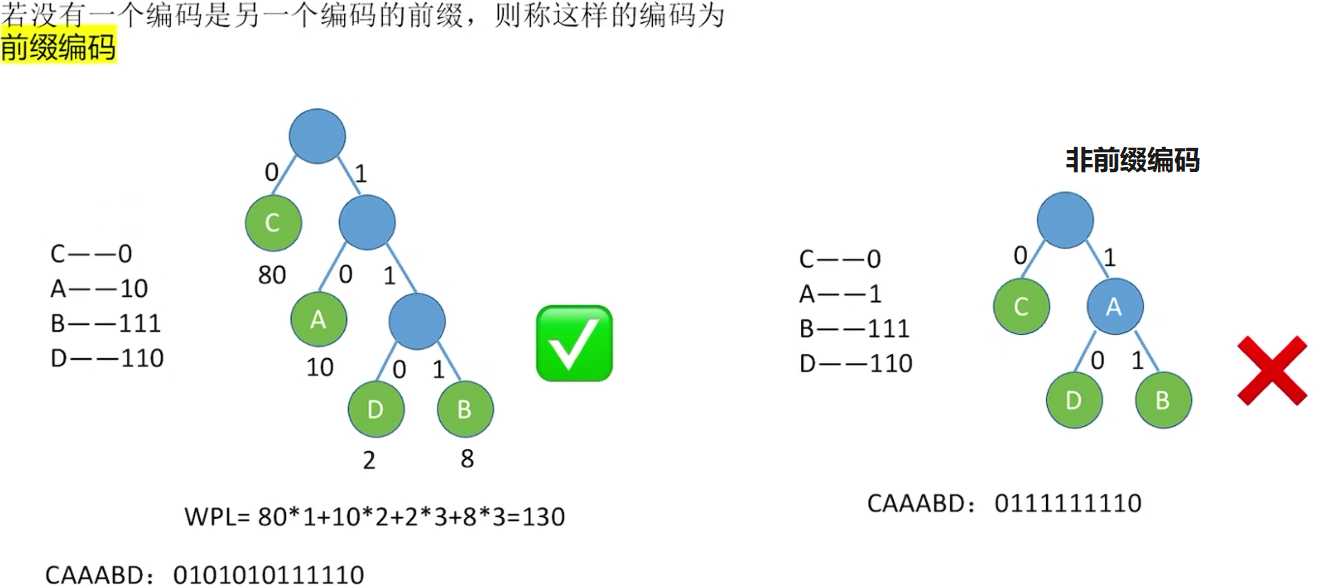
5.2.1 并查集
在集合这种逻辑结构中,两个元素之间的关系是从属于同一集合或从属于不同集合。使用树来表示一个集合,双亲表示法(顺序存储)更适合实现并查集 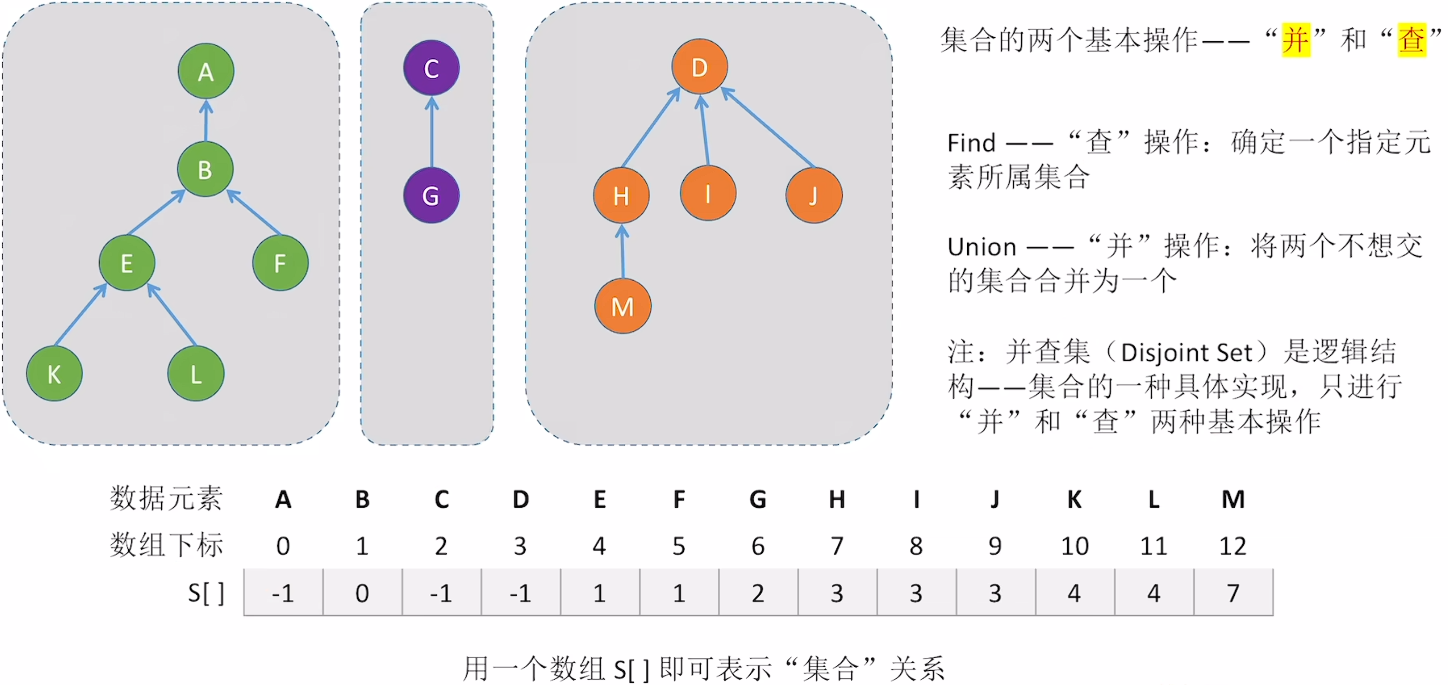
代码实现
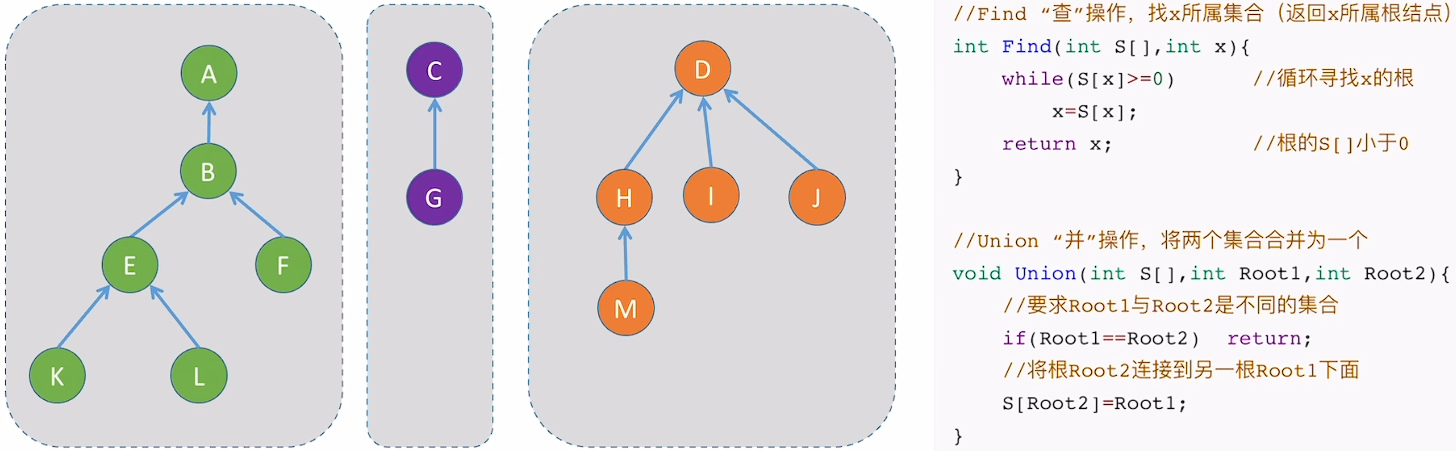
性能分析
时间复杂度:Find:O(n) ,Union:O(1) 对于合并集合(树)的过程,要尽可能的树“矮胖”(小树合并到大树中),以在Find的过程过程中尽可能减少访问结点的次数: 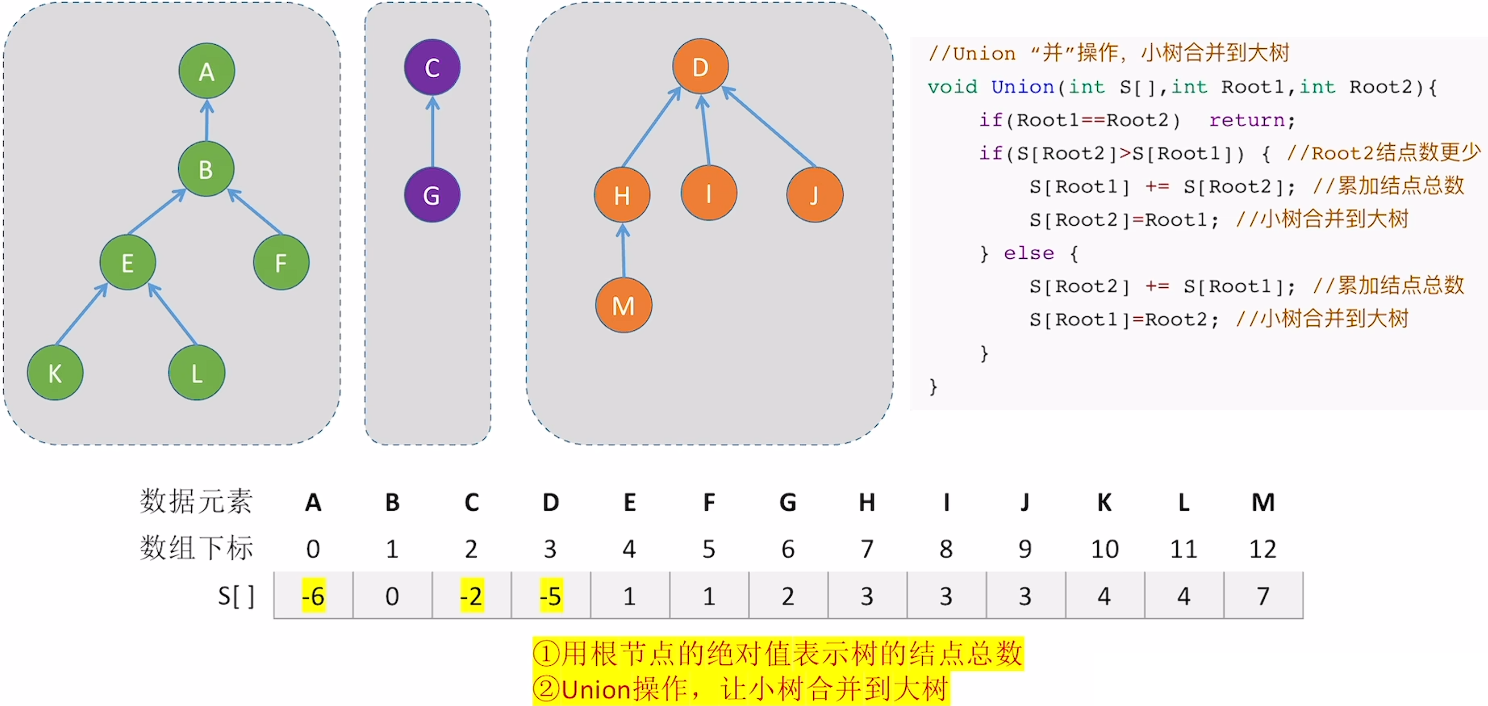
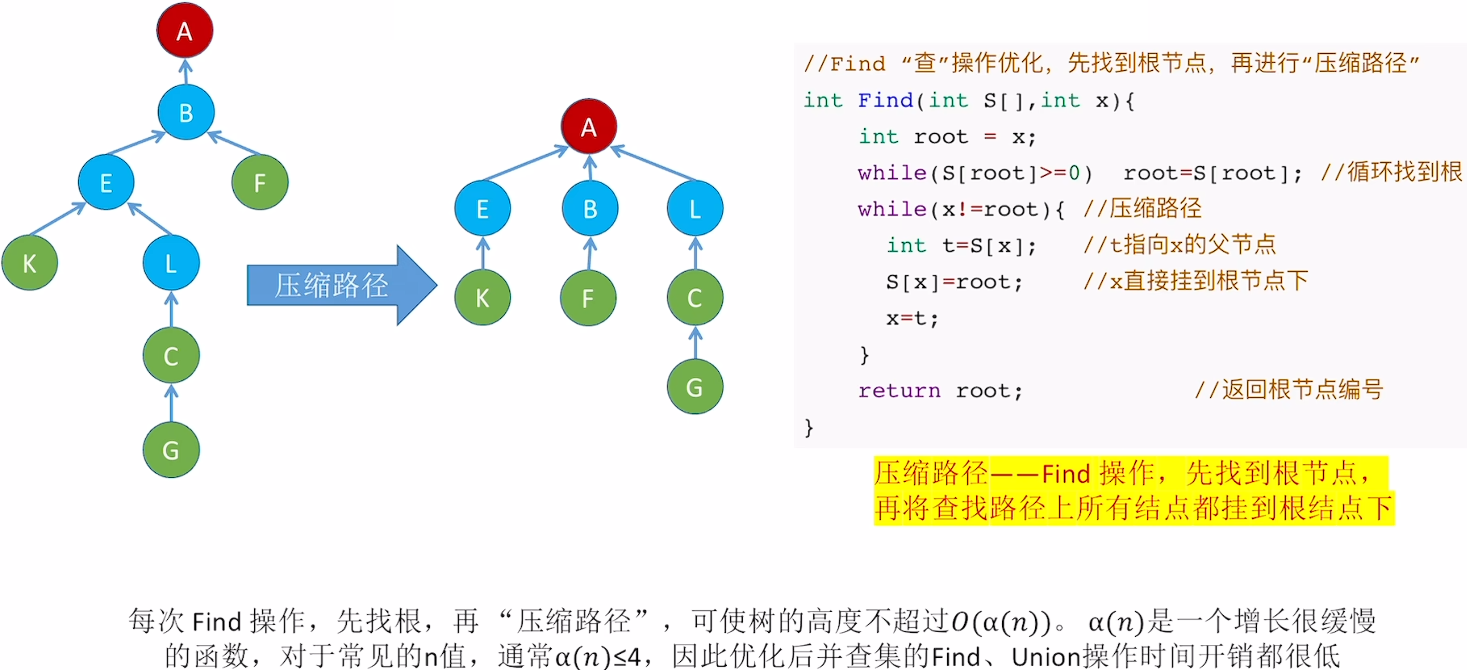
算法优化
优化Union: 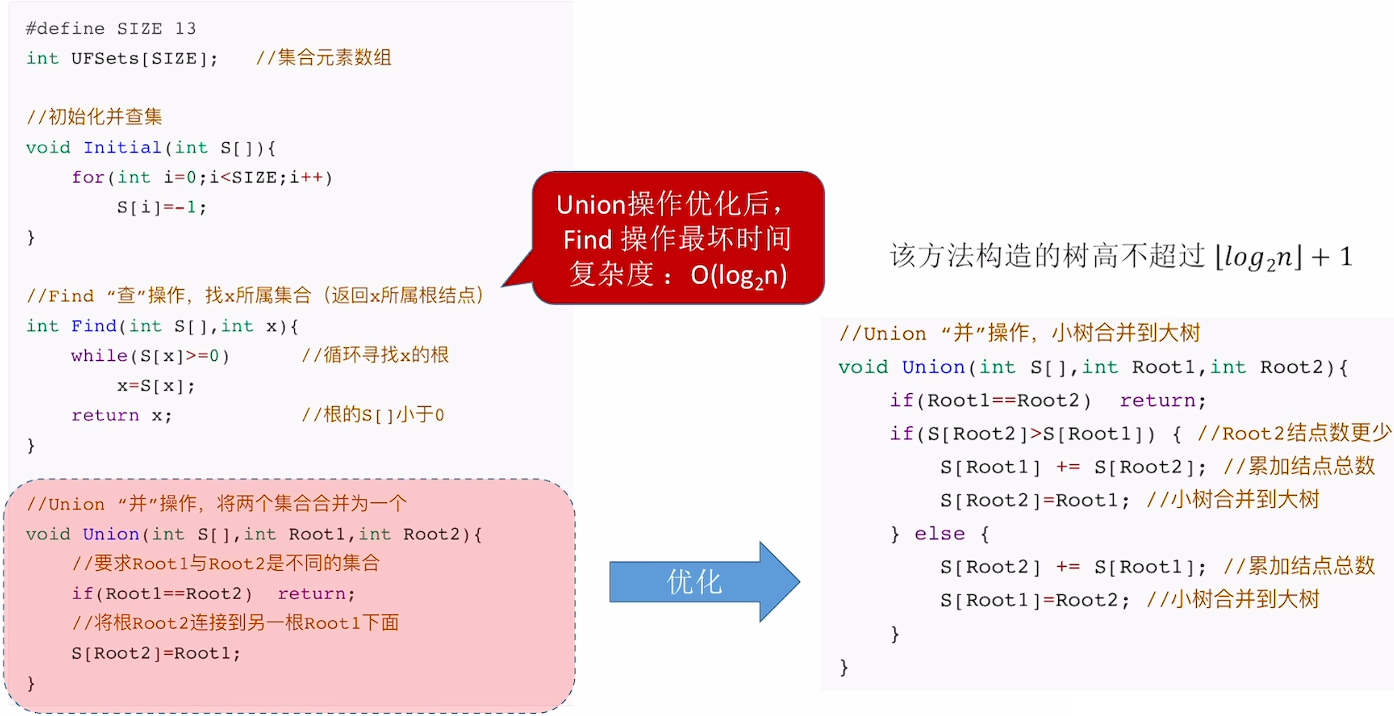
优化Find: