tag-based-graph-recommender
==在制作 PPT 的时候,类似在 clean_tag 方法、某某函数,太过于具体的字样就不要写了,直接阐述函数的功能就行==
算法实现思路
这个推荐算法的核心思想是通过电影和标签之间的关系,结合用户的标签偏好,通过构建一个图结构,将用户、电影和标签作为节点,节点之间的边代表了它们之间的关系。
1. 标签整理:
标签数据是非常关键的部分,特别是对于文本数据,常常会有很多不必要的噪音。
标签文本清理:在
clean_tag方法中,首先对标签文本进行基础的清理。它会:- 去除标签的前后空白字符,转化为小写,确保一致性。
- 删除一些无意义的标签(例如“favorite”、“good”、“bad”等常见的评价性标签),这些标签对推荐系统没有帮助。
- 只保留字母、数字和空格,删除特殊字符。
- 合并多个空格为一个空格,避免不必要的格式问题。
清洗后的标签:清洗过后的标签会存储在
cleaned_tag字段中,只有有效的标签才会进入后续的分析和图构建。这一步的好处是,它过滤掉了那些对推荐系统影响不大的噪声数据,使得推荐更加精准。
2. 标签的选择:
如何选择有效标签?主要依赖于以下几步:
标签频率统计:通过
analyze_tags方法,系统会分析清理后的标签数据,统计每个标签出现的频率,得到最常见的标签。最常见的标签能代表大多数用户的兴趣,算法会优先考虑这些标签。用户标签使用统计:系统会计算每个用户使用的标签数量,了解每个用户的标签活跃度。那些使用标签较为频繁的用户,可能有更明确的标签偏好,算法会优先考虑这些用户的标签。
标签与电影的关系:每个标签和电影之间都会建立边,并附带权重。这些权重反映了标签和电影的关联度。算法根据电影的标签,推测哪些电影可能符合用户的兴趣。
3. 算法整体实现分析
图结构的构建:
基本信息:
- 总节点数: 11838
- 总边数: 89396
- 节点类型分布:
- movie: 9742 个节点
- tag: 1487 个节点
- user: 609 个节点
整个推荐系统的核心在于一个图模型。图中有三类节点:用户(user)、电影(movie)和标签(tag)。这些节点通过边相连,表示不同的关系:
- 用户和电影之间的边表示用户对电影的评分。
- 用户和标签之间的边表示用户对某个标签的偏好。
- 电影和标签之间的边表示电影和标签的关联度。
这个图结构在引入了标签的同时考虑了用户和电影之间的关系,进一步丰富了推荐的维度。
推荐过程:
- 基于标签的推荐:首先,算法会根据用户偏好的标签(即用户在标签图中的权重)来推测用户可能感兴趣的电影。如果某个标签在电影中出现频率较高,并且这个标签对用户的偏好较高,那么与这个标签相关的电影将被优先推荐。
- 基于用户的推荐:除了标签,系统还会通过计算用户之间的相似性,来推荐其他用户喜欢的电影。这种相似性是基于用户共同观看过的电影或共同喜欢的标签来计算的。
- 融合推荐分数:最后,标签推荐和用户推荐的分数会进行加权合并,生成最终的推荐列表。系统使用了
alpha和beta参数来调节这两种推荐策略的权重。
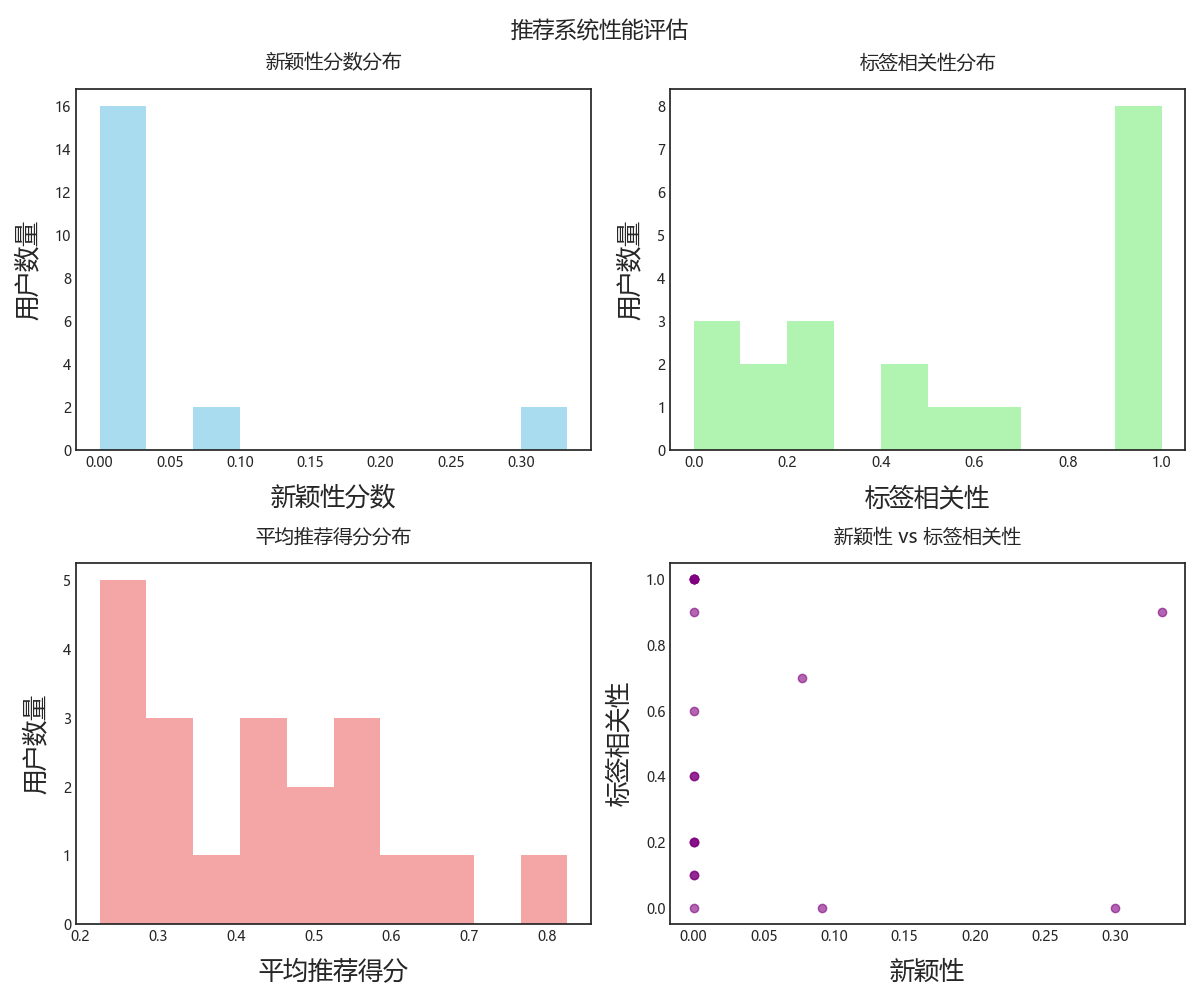
推荐结果分析:
- 评估用户数量: 50
- 用户覆盖率: 1.0
- 平均新颖性: 0.04
- 平均标签相关性: 0.535
- 平均推荐得分: 0.438
- 覆盖类型数量: 18
- 类型分布:分析推荐电影的类型,看看是否符合用户的历史兴趣。
- 新颖性:计算推荐结果与用户历史兴趣的差异程度。新颖性高的推荐可能会带来意想不到的惊喜。
- 标签相关性:检查推荐的电影与用户偏好的标签之间的匹配度。如果推荐的电影标签与用户的偏好标签一致,说明推荐结果更加符合用户兴趣。